BFS: búsqueda por anchura en grafos y árboles
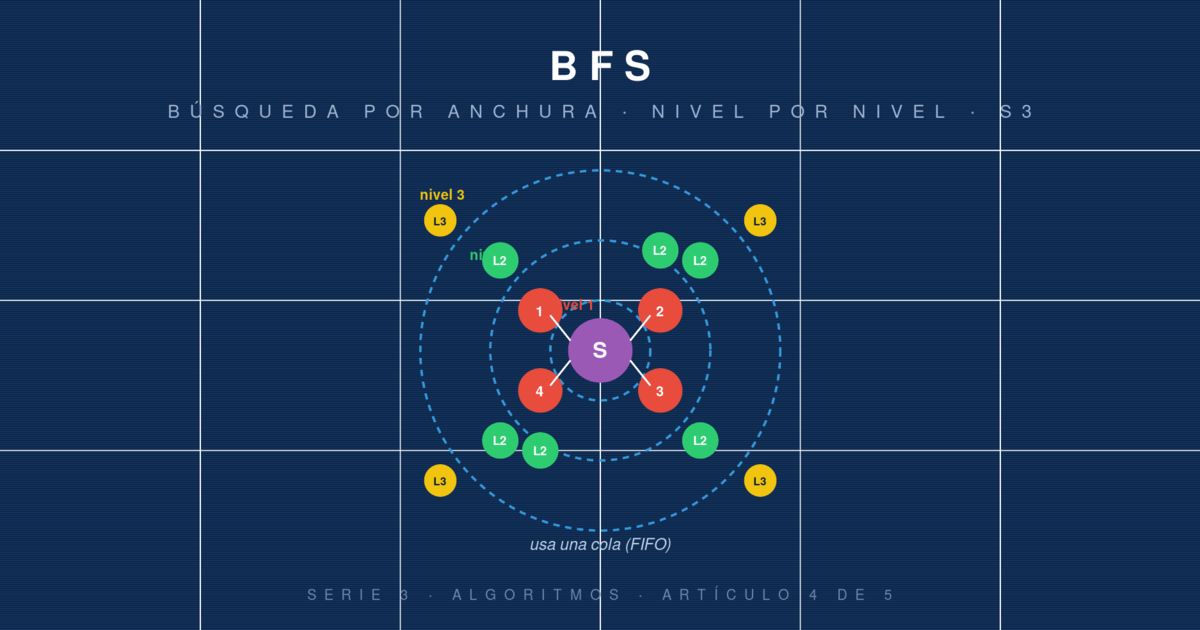
Cuando estudiamos los recorridos de árbol vimos preorden, inorden y postorden: los tres son variantes de DFS, exploración en profundidad. Queda uno que no encaja en esa familia: el recorrido por niveles, conocido como BFS (Breadth-First Search). En lugar de bajar por una rama hasta el fondo y retroceder, BFS explora primero todos los nodos a distancia 1 del origen, luego todos los de distancia 2, luego los de distancia 3, etc.
Ese patrón tiene una propiedad matemática muy importante: BFS garantiza encontrar el camino más corto (en número de aristas) desde el origen hasta cualquier otro nodo en un grafo sin peso. Por eso aparece en redes sociales ("grados de separación"), en routing, en videojuegos (pathfinding básico), en autómatas y en crawlers web.
Este es el cuarto artículo de Cómo se busca y se recorre.
La idea central
Imagina una onda en un estanque: tiras una piedra y se expande en círculos concéntricos. BFS hace lo mismo sobre un grafo:
Nivel 0: el origen.
Nivel 1: todos los vecinos del origen.
Nivel 2: todos los vecinos de los del nivel 1 que aún no fueron visitados.
Y así sucesivamente.
Para implementarlo necesitamos:
Una cola donde metemos los nodos descubiertos pero aún no procesados.
Un conjunto de visitados para no repetir trabajo ni entrar en ciclos.
El algoritmo:
inicializar cola con el origen
marcar origen como visitado
mientras la cola no esté vacía:
sacar el primero de la cola → v
procesar v
para cada vecino de v:
si el vecino no fue visitado:
marcarlo visitado
meterlo en la cola
La cola garantiza el orden FIFO, que a su vez garantiza la exploración por niveles.
Ejemplo paso a paso
Considera este grafo:
A
/ \
B C
/| |\
D E F G
BFS desde A:
cola: [A] visitados: {A} → procesar A
cola: [B, C] visitados: {A, B, C} → procesar B
cola: [C, D, E] visitados: {A, B, C, D, E} → procesar C
cola: [D, E, F, G] visitados: {A, B, C, D, E, F, G} → procesar D
cola: [E, F, G] ... procesar E
cola: [F, G] ... procesar F
cola: [G] ... procesar G
cola: [] fin
Orden de procesamiento: A, B, C, D, E, F, G. Exactamente por niveles.
Implementación en PHP
function bfs(array $grafo, string $origen): array {
$orden = [];
$visitados = [$origen => true];
$cola = [$origen];
while (!empty($cola)) {
$v = array_shift($cola);
$orden[] = $v;
foreach ($grafo[$v] ?? [] as $vecino) {
if (!isset($visitados[$vecino])) {
$visitados[$vecino] = true;
$cola[] = $vecino;
}
}
}
return $orden;
}
$grafo = [
"A" => ["B", "C"],
"B" => ["A", "D", "E"],
"C" => ["A", "F", "G"],
"D" => ["B"], "E" => ["B"],
"F" => ["C"], "G" => ["C"],
];
print_r(bfs($grafo, "A")); // [A, B, C, D, E, F, G]
Ojo: array_shift es O(n). Para colas grandes, usa SplQueue:
$cola = new SplQueue();
$cola->enqueue($origen);
while (!$cola->isEmpty()) {
$v = $cola->dequeue();
...
}
Implementación en Java
import java.util.*;
public static <T> List<T> bfs(Map<T, List<T>> grafo, T origen) {
List<T> orden = new ArrayList<>();
Set<T> visitados = new HashSet<>();
Queue<T> cola = new ArrayDeque<>();
cola.offer(origen);
visitados.add(origen);
while (!cola.isEmpty()) {
T v = cola.poll();
orden.add(v);
for (T vecino : grafo.getOrDefault(v, List.of())) {
if (visitados.add(vecino)) {
cola.offer(vecino);
}
}
}
return orden;
}
El método Set.add(x) devuelve true si el elemento no estaba; lo aprovechamos para chequear y marcar en una sola llamada.
Camino más corto: la aplicación estrella
La propiedad fundamental de BFS es: en un grafo sin peso, la primera vez que visitas un nodo, lo haces por el camino más corto. Esto nos permite calcular distancias trivialmente.
public static <T> Map<T, Integer> distancias(Map<T, List<T>> grafo, T origen) {
Map<T, Integer> dist = new HashMap<>();
dist.put(origen, 0);
Queue<T> cola = new ArrayDeque<>();
cola.offer(origen);
while (!cola.isEmpty()) {
T v = cola.poll();
for (T vecino : grafo.getOrDefault(v, List.of())) {
if (!dist.containsKey(vecino)) {
dist.put(vecino, dist.get(v) + 1);
cola.offer(vecino);
}
}
}
return dist;
}
Y si además quieres reconstruir la ruta, guarda el predecesor:
public static <T> List<T> caminoMasCorto(Map<T, List<T>> grafo, T origen, T destino) {
Map<T, T> prev = new HashMap<>();
prev.put(origen, null);
Queue<T> cola = new ArrayDeque<>();
cola.offer(origen);
while (!cola.isEmpty()) {
T v = cola.poll();
if (v.equals(destino)) {
List<T> camino = new ArrayList<>();
for (T x = destino; x != null; x = prev.get(x)) camino.add(x);
Collections.reverse(camino);
return camino;
}
for (T vecino : grafo.getOrDefault(v, List.of())) {
if (!prev.containsKey(vecino)) {
prev.put(vecino, v);
cola.offer(vecino);
}
}
}
return List.of(); // no conectados
}
BFS en árboles: recorrido por niveles
Si aplicas BFS a un árbol (que es un caso especial de grafo), obtienes el clásico "recorrido por niveles":
public static void porNiveles(Nodo raiz) {
if (raiz == null) return;
Queue<Nodo> cola = new ArrayDeque<>();
cola.offer(raiz);
while (!cola.isEmpty()) {
Nodo n = cola.poll();
System.out.print(n.valor + " ");
if (n.izq != null) cola.offer(n.izq);
if (n.der != null) cola.offer(n.der);
}
}
Si quieres saber en qué nivel está cada nodo, procesa toda una capa antes de bajar:
public static void porNivelesSeparados(Nodo raiz) {
if (raiz == null) return;
Queue<Nodo> cola = new ArrayDeque<>();
cola.offer(raiz);
int nivel = 0;
while (!cola.isEmpty()) {
int size = cola.size();
System.out.print("Nivel " + nivel + ": ");
for (int i = 0; i < size; i++) {
Nodo n = cola.poll();
System.out.print(n.valor + " ");
if (n.izq != null) cola.offer(n.izq);
if (n.der != null) cola.offer(n.der);
}
System.out.println();
nivel++;
}
}
Ese patrón (fijar el size al inicio de cada nivel) es estándar en preguntas tipo "minimum depth", "right side view" y otros problemas de árbol por niveles.
Complejidad
Para un grafo con V vértices y E aristas:
MétricaBFSTiempoO(V + E)EspacioO(V) — cola + set de visitados
Cada vértice entra a la cola una sola vez (amortizado por el set de visitados) y cada arista se examina una sola vez.
DFS vs BFS: ¿cuándo usar cuál?
CaracterísticaBFSDFSEstructuraColaPila (o recursión)OrdenPor nivelesPor profundidadCamino más corto (sin peso)SíNo garantizadoUso de memoriaO(ancho máximo)O(profundidad máxima)Típico en árboles muy anchosCostosoEficienteTípico en árboles muy profundosEficienteCostosoDetección de ciclosPosibleMás naturalComponentes conexasSíSíOrdenamiento topológicoNoSí
BFS es la elección cuando quieres la distancia mínima en número de pasos, cuando procesas por niveles (simulación de propagación, rondas), o cuando el grafo tiene profundidad ilimitada pero ancho limitado (crawlers, AIs en juegos).
Ventajas y desventajas
Ventajas:
Encuentra el camino más corto sin peso.
Orden por niveles, útil en muchísimas aplicaciones.
Fácil de implementar iterativamente (usa cola).
Evita stack overflow al no ser recursivo.
Desventajas:
Memoria: en grafos muy anchos la cola puede crecer mucho (peor caso O(V)).
No produce orden topológico.
En grafos ponderados no da el camino más corto (necesitas Dijkstra).
Casos de uso reales
Grados de separación en redes sociales.
Crawlers web: recorren páginas por niveles para cubrir internet sin perderse por una rama infinita.
Pathfinding sin peso en videojuegos 2D sobre grillas.
Broadcast en redes: simular propagación de un mensaje por toda la topología.
Análisis de componentes conexas en imágenes (flood fill).
Validación de laberintos ("¿es posible llegar del inicio al fin?").
Serialización por niveles de árboles.
Detección de bipartitos: BFS coloreando cada nivel alternadamente.
Variantes útiles
Flood fill
El "rellenar con color" de Paint y Photoshop es BFS (o DFS) sobre una grilla 2D, donde cada celda es un nodo y las aristas son las 4 (u 8) celdas vecinas. Empieza en el punto clicado, y expande a todos los vecinos del mismo color inicial.
void floodFill(int[][] img, int r, int c, int nuevoColor) {
int original = img[r][c];
if (original == nuevoColor) return;
Queue<int[]> cola = new ArrayDeque<>();
cola.offer(new int[]{r, c});
while (!cola.isEmpty()) {
int[] p = cola.poll();
int i = p[0], j = p[1];
if (i < 0 || i >= img.length || j < 0 || j >= img[0].length) continue;
if (img[i][j] != original) continue;
img[i][j] = nuevoColor;
cola.offer(new int[]{i+1, j});
cola.offer(new int[]{i-1, j});
cola.offer(new int[]{i, j+1});
cola.offer(new int[]{i, j-1});
}
}
BFS bidireccional
Para acelerar el cálculo de camino más corto entre dos nodos específicos, ejecuta BFS simultáneamente desde origen y destino. Cuando se encuentran, has encontrado el camino más corto. Reduce la complejidad de O(b^d) a O(b^(d/2)) donde b es el branching factor.
0-1 BFS
Si el grafo tiene pesos solo 0 o 1, puedes usar una doble cola (deque) en lugar de una cola normal. Aristas de peso 0 se añaden al frente y las de peso 1 al final. Mantiene la complejidad O(V + E).
Errores comunes
1. Marcar visitado al sacar, no al meter
// MAL
while (!cola.isEmpty()) {
T v = cola.poll();
if (visitados.contains(v)) continue;
visitados.add(v);
...
}
Este patrón funciona pero puede meter el mismo nodo varias veces a la cola, explotando la memoria. La versión correcta marca visitado al meter en la cola:
if (visitados.add(vecino)) cola.offer(vecino);
2. Usar BFS en grafos ponderados esperando camino más corto
Solo garantiza menor número de aristas, no menor costo total. Para pesos, usa Dijkstra.
3. Olvidar el set de visitados en grafos con ciclos
Sin visitados, un ciclo A → B → A → B → ... explota en memoria y nunca termina.
4. Confundir BFS con DFS al implementar
El único cambio entre una implementación iterativa de BFS y DFS es la estructura: cola vs pila. Leer el código con atención salva de confusiones.
5. Usar LinkedList como cola por defecto en Java
LinkedList implementa Queue, pero es menos eficiente que ArrayDeque. Prefiere ArrayDeque salvo razón muy específica.
6. Asumir que BFS detecta ciclos "gratis"
Sí los detecta si estás construyendo un árbol de BFS, pero los matices en grafos dirigidos (detectar ciclos direccionales) los maneja mejor DFS con estados blanco/gris/negro.
Resumen
BFS recorre un grafo por niveles usando una cola y un set de visitados. Es O(V + E) en tiempo y O(V) en memoria. Su propiedad clave es que, en grafos sin peso, encuentra el camino más corto desde el origen a cualquier otro nodo.
Se aplica en redes sociales (grados de separación), crawlers web, pathfinding, flood fill, broadcast, análisis de componentes conexas y procesamiento por niveles en árboles. Para grafos ponderados, la generalización es Dijkstra.
En el último artículo de la serie vemos la alternativa: DFS, el recorrido en profundidad, y las aplicaciones donde es claramente superior (ordenamiento topológico, detección de ciclos, backtracking).
DFS: recorrido en profundidad, backtracking y la base de muchos algoritmos
Depth-First Search se sumerge hasta el fondo antes de retroceder. Usado en backtracking, detección de ciclos y ordenamiento topológico. Vers...
Recorridos de árboles: inorden, preorden y postorden explicados
Las tres formas clásicas de visitar todos los nodos de un árbol binario. Cuál usar depende del orden en que necesitas los datos. Ejemplos co...

Búsqueda binaria: cómo encontrar algo entre millones en 20 pasos
obre un array ordenado, cortar por la mitad repetidamente encuentra cualquier elemento en tiempo logarítmico. Implementación correcta y por...
Comentarios (0)
Sé el primero en comentar.
Deja un comentario