DFS: recorrido en profundidad, backtracking y la base de muchos algoritmos
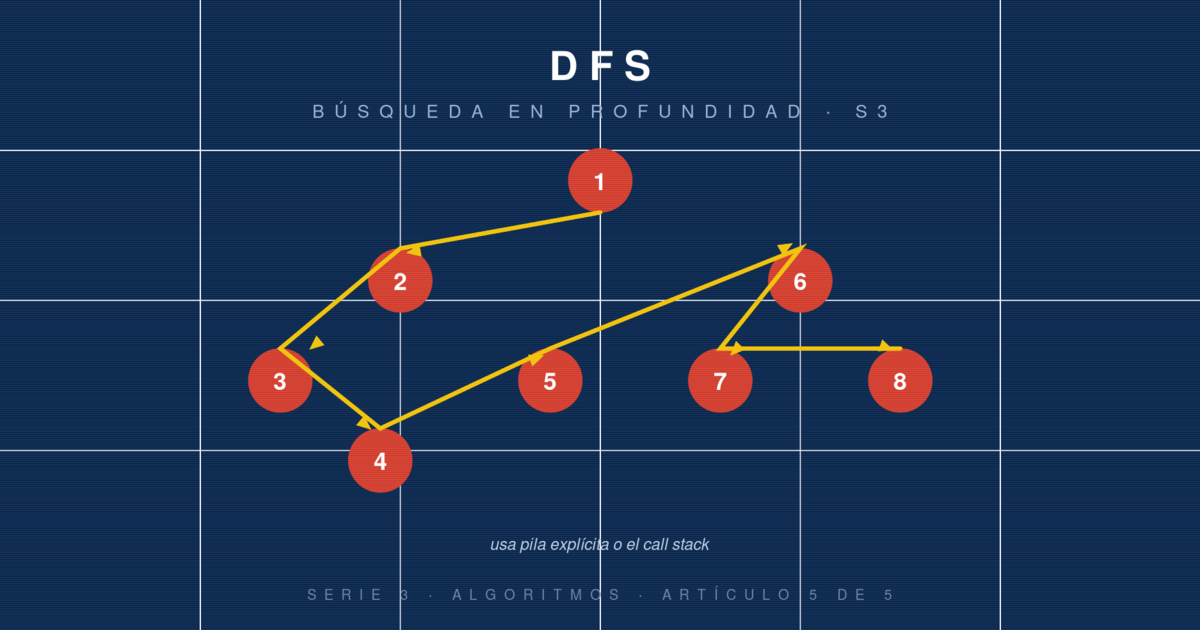
Si BFS se expande por ondas concéntricas, DFS (Depth-First Search) es todo lo contrario: baja por una rama hasta el final, retrocede un paso cuando no puede avanzar más, prueba otra rama, y así sucesivamente. Es el patrón natural al explorar un laberinto, al evaluar jugadas en un juego, al resolver un sudoku, al evaluar dependencias antes de instalar un paquete.
DFS es el algoritmo detrás de: ordenamiento topológico, detección de ciclos, componentes conexas en grafos dirigidos, generación de permutaciones y combinaciones, resolución de puzzles con backtracking, análisis de árboles sintácticos, y miles de patrones de exploración recursiva. Si dominas DFS y recursión, media biblioteca de algoritmos se vuelve legible de inmediato.
Este es el quinto y último artículo de Cómo se busca y se recorre, y también el que cierra el blog introductorio a las ciencias de la computación.
La idea central
Empezamos en un nodo. Lo marcamos como visitado. Para cada vecino no visitado, recursivamente hacemos DFS desde él. El orden de visita depende del orden de los vecinos y de la estructura del grafo, pero siempre exploramos "lo más profundo que podamos" antes de retroceder.
Recursivamente:
DFS(v):
marcar v como visitado
procesar v
para cada vecino w de v:
si w no ha sido visitado:
DFS(w)
Iterativamente, reemplazamos la recursión por una pila explícita. El único cambio respecto a BFS es el reemplazo de cola por pila.
Ejemplo paso a paso
Grafo:
A
/ \
B C
/| |\
D E F G
DFS desde A (explorando primero hijo izquierdo):
visitar A
visitar B
visitar D (hoja, retrocede)
visitar E (hoja, retrocede)
visitar C
visitar F (hoja, retrocede)
visitar G (hoja, retrocede)
Orden de procesamiento: A, B, D, E, C, F, G.
Comparación con BFS: A, B, C, D, E, F, G. Mismo grafo, distinto orden.
Implementación recursiva en PHP
function dfs(array $grafo, string $origen, array &$visitados = [], array &$orden = []): array {
$visitados[$origen] = true;
$orden[] = $origen;
foreach ($grafo[$origen] ?? [] as $vecino) {
if (!isset($visitados[$vecino])) {
dfs($grafo, $vecino, $visitados, $orden);
}
}
return $orden;
}
$grafo = [
"A" => ["B", "C"],
"B" => ["D", "E"],
"C" => ["F", "G"],
"D" => [], "E" => [], "F" => [], "G" => [],
];
print_r(dfs($grafo, "A")); // [A, B, D, E, C, F, G]
Implementación recursiva en Java
public static <T> List<T> dfs(Map<T, List<T>> grafo, T origen) {
List<T> orden = new ArrayList<>();
Set<T> visitados = new HashSet<>();
dfsRec(grafo, origen, visitados, orden);
return orden;
}
private static <T> void dfsRec(Map<T, List<T>> grafo, T v, Set<T> visitados, List<T> orden) {
if (!visitados.add(v)) return;
orden.add(v);
for (T vecino : grafo.getOrDefault(v, List.of())) {
dfsRec(grafo, vecino, visitados, orden);
}
}
Implementación iterativa con pila
Si la profundidad del grafo es grande, la recursión puede desbordar el stack. La versión iterativa usa una pila explícita:
public static <T> List<T> dfsIter(Map<T, List<T>> grafo, T origen) {
List<T> orden = new ArrayList<>();
Set<T> visitados = new HashSet<>();
Deque<T> pila = new ArrayDeque<>();
pila.push(origen);
while (!pila.isEmpty()) {
T v = pila.pop();
if (visitados.add(v)) {
orden.add(v);
// para preservar orden de los vecinos, itera en reversa
List<T> vecinos = grafo.getOrDefault(v, List.of());
for (int i = vecinos.size() - 1; i >= 0; i--) {
T w = vecinos.get(i);
if (!visitados.contains(w)) pila.push(w);
}
}
}
return orden;
}
Complejidad
Para un grafo con V vértices y E aristas:
MétricaDFSTiempoO(V + E)Espacio (recursivo)O(V) — pila de llamadasEspacio (iterativo)O(V) — pila explícita
Misma complejidad que BFS; el coste de cambiar de cola a pila es cero.
Aplicaciones clave de DFS
Donde DFS destaca sobre BFS:
1. Ordenamiento topológico
En un DAG (grafo dirigido acíclico), queremos listar los vértices en orden tal que, si hay una arista u → v, entonces u aparece antes que v. Esto resuelve problemas como:
Compilar archivos en el orden correcto (cada archivo depende de otros).
Instalar paquetes: resolver dependencias antes del paquete que las necesita.
Schedulers de tareas con precedencias.
Evaluar fórmulas en una hoja de cálculo.
Algoritmo basado en DFS (variación): ejecuta DFS desde cada vértice no visitado; cuando terminas de procesar un vértice (postorden), lo añades a una lista. Al final, invierte la lista:
public static <T> List<T> ordenTopologico(Map<T, List<T>> grafo) {
Set<T> visitados = new HashSet<>();
Deque<T> pila = new ArrayDeque<>();
for (T v : grafo.keySet()) {
if (!visitados.contains(v)) topoRec(grafo, v, visitados, pila);
}
List<T> orden = new ArrayList<>();
while (!pila.isEmpty()) orden.add(pila.pop());
return orden;
}
private static <T> void topoRec(Map<T, List<T>> grafo, T v, Set<T> visitados, Deque<T> pila) {
visitados.add(v);
for (T vecino : grafo.getOrDefault(v, List.of())) {
if (!visitados.contains(vecino)) topoRec(grafo, vecino, visitados, pila);
}
pila.push(v); // postorden: al terminar
}
2. Detección de ciclos en grafos dirigidos
Clasifica cada vértice en tres estados mientras ejecutas DFS:
Blanco: no visitado.
Gris: en la pila de recursión actual (se está procesando).
Negro: procesamiento completo.
Si durante DFS encuentras un vecino gris, hay un ciclo:
enum Color { BLANCO, GRIS, NEGRO }
public static <T> boolean tieneCiclo(Map<T, List<T>> grafo) {
Map<T, Color> color = new HashMap<>();
for (T v : grafo.keySet()) color.put(v, Color.BLANCO);
for (T v : grafo.keySet()) {
if (color.get(v) == Color.BLANCO && ciclo(grafo, v, color)) return true;
}
return false;
}
private static <T> boolean ciclo(Map<T, List<T>> grafo, T v, Map<T, Color> color) {
color.put(v, Color.GRIS);
for (T vecino : grafo.getOrDefault(v, List.of())) {
if (color.get(vecino) == Color.GRIS) return true;
if (color.get(vecino) == Color.BLANCO && ciclo(grafo, vecino, color)) return true;
}
color.put(v, Color.NEGRO);
return false;
}
3. Componentes conexas / fuertemente conexas
Para contar cuántos subgrafos aislados tiene un grafo, ejecutas DFS desde cada vértice no visitado y cada invocación exterior representa una componente:
int componentes = 0;
Set<T> visitados = new HashSet<>();
for (T v : grafo.keySet()) {
if (!visitados.contains(v)) {
componentes++;
dfsRec(grafo, v, visitados, new ArrayList<>());
}
}
Para componentes fuertemente conexas en grafos dirigidos, existen los algoritmos de Tarjan y Kosaraju, ambos basados en DFS.
4. Backtracking
DFS es la columna vertebral del backtracking: explora una posibilidad, si no funciona retrocede y prueba otra. Los problemas clásicos son:
N-Reinas: colocar N reinas en un tablero N×N sin que se ataquen.
Sudoku: elegir un número por casilla, si lleva a contradicción retroceder.
Subset sum: elegir un subconjunto que sume a un objetivo.
Permutaciones y combinaciones.
Word break: partir un string en palabras de un diccionario.
Generación de laberintos y su resolución.
Ejemplo: generar todas las permutaciones de un array.
public static List<List<Integer>> permutaciones(int[] nums) {
List<List<Integer>> res = new ArrayList<>();
backtrack(res, new ArrayList<>(), nums, new boolean[nums.length]);
return res;
}
private static void backtrack(List<List<Integer>> res, List<Integer> actual, int[] nums, boolean[] usado) {
if (actual.size() == nums.length) {
res.add(new ArrayList<>(actual));
return;
}
for (int i = 0; i < nums.length; i++) {
if (usado[i]) continue;
actual.add(nums[i]);
usado[i] = true;
backtrack(res, actual, nums, usado);
actual.remove(actual.size() - 1); // retroceder
usado[i] = false;
}
}
La estructura es idéntica a DFS: elegir, recurrir, deshacer.
5. Recorridos de árbol
Los recorridos preorden, inorden y postorden son casos particulares de DFS en árboles binarios. Los vimos en el artículo anterior.
6. Resolver laberintos
Dada una grilla con paredes, encontrar un camino del inicio a la salida. DFS naturalmente explora un camino hasta el final, y si choca con pared o ya visitado, retrocede.
DFS vs BFS: resumen
ObjetivoMejor opciónCamino más corto en grafo sin pesoBFSOrdenamiento topológicoDFSDetección de ciclosDFS (con estados)BacktrackingDFSComponentes fuertemente conexasDFSFlood fillambosExploración exhaustivaambosProfundidad ilimitada, ancho limitadoBFSAncho ilimitado, profundidad limitadaDFS
Ventajas y desventajas
Ventajas:
Implementación natural con recursión (3-4 líneas en su forma más simple).
Memoria proporcional a la profundidad, no al ancho.
Base de muchísimos algoritmos clásicos.
Extensiones con estados (blanco/gris/negro) resuelven problemas difíciles elegantemente.
Desventajas:
No garantiza camino más corto.
Recursión profunda puede desbordar el stack (usa iterativo en árboles muy profundos).
Puede "perderse" en ramas profundas e infinitas si no hay control.
Casos de uso reales
Instaladores de paquetes (npm, pip, Maven, apt): ordenamiento topológico de dependencias.
Compiladores: recorrido del AST en postorden para generar código.
Resolución de puzzles (sudoku, crucigramas, N-reinas).
Detección de deadlocks en sistemas operativos: ciclos en el grafo de procesos y recursos.
Análisis estático de código: call graph, dead code detection.
Renderizado de árboles en UIs: React reconciliation hace un recorrido DFS.
Serializadores (JSON, XML, Protobuf): DFS sobre el objeto.
Generación y resolución de laberintos.
Evaluadores de expresiones en intérpretes.
Crawlers dirigidos que exploran sitios con profundidad limitada.
Ejemplo aplicado: resolver un Sudoku
El Sudoku es el "hola mundo" del backtracking. La idea: encuentra una celda vacía, prueba cada dígito del 1 al 9, si es válido recursivamente intenta resolver el resto. Si ninguno funciona, retrocede.
public static boolean resolver(int[][] tablero) {
for (int r = 0; r < 9; r++) {
for (int c = 0; c < 9; c++) {
if (tablero[r][c] == 0) {
for (int n = 1; n <= 9; n++) {
if (esValido(tablero, r, c, n)) {
tablero[r][c] = n;
if (resolver(tablero)) return true;
tablero[r][c] = 0; // retroceder
}
}
return false; // ningún dígito funcionó
}
}
}
return true; // no quedan celdas vacías
}
40 líneas de código resuelven cualquier sudoku. DFS puro.
Errores comunes
1. Recursión demasiado profunda
En un árbol desbalanceado de un millón de nodos, la recursión genera un millón de stack frames. Java lanza StackOverflowError. Usa la versión iterativa con pila explícita, o aumenta el stack con -Xss.
2. Olvidar marcar visitados en grafos con ciclos
Sin visitados, DFS entra en bucle infinito. En árboles no es necesario (no hay ciclos), en grafos generales sí.
3. Marcar visitados en el lugar incorrecto
Al principio de la función recursiva, no al encolar. A diferencia de BFS, en DFS se marca al entrar a la función.
4. Confundir backtracking con pure DFS
En backtracking se "deshace" el estado al retroceder (quitar el elemento de la lista actual, poner 0 en la casilla del sudoku). En DFS puro (recorrido), no se deshace nada. Mezclar los paradigmas produce bugs sutiles.
5. Asumir que DFS visita en el mismo orden con recursión e iterativo
Las versiones iterativas con pila invierten el orden natural de los hijos. Si el orden importa, itera la lista de vecinos en reversa al empujarlos a la pila.
6. No usar los estados blanco/gris/negro para detección de ciclos
Marcar solo "visitado/no visitado" no detecta ciclos dirigidos. Necesitas los tres estados para saber si el vecino está en la cadena actual de recursión o si ya se completó.
7. Crear nuevos HashSets en cada llamada recursiva
Un bug habitual que dispara la memoria. El set de visitados debe ser compartido entre todas las llamadas recursivas, no local a cada una.
Un último consejo práctico
Cuando te encuentres con un problema que pida "explorar todas las posibilidades", "encontrar un camino", "generar todas las combinaciones", "resolver un puzzle", "detectar un ciclo" o "procesar dependencias", mentalmente traduce a: "este es un problema de DFS / backtracking". La estructura será casi siempre la misma:
Estado actual.
Caso base (condición de éxito o fracaso).
Bucle sobre opciones.
Elegir → recurrir → deshacer.
Con práctica, ese patrón se vuelve la lente con la que lees problemas complejos.
Resumen
DFS recorre en profundidad: baja por una rama hasta el final, retrocede, prueba otra. Se implementa con recursión o con pila explícita, y comparte la complejidad O(V + E) con BFS. Su orden de exploración lo hace ideal para ordenamiento topológico, detección de ciclos, análisis de componentes, backtracking, resolución de puzzles y recorridos de árboles.
Junto con BFS, cubren la inmensa mayoría de algoritmos de recorrido en grafos y árboles. Dominar ambos —saber cuándo usar cada uno— es una de las habilidades de mayor ROI que puedes adquirir como programador.
Cierre de la serie
Con este artículo cerramos el recorrido por las ciencias de la computación: desde Iteración hasta aquí pasamos por recursión, Big-O, stack y heap, todas las estructuras de datos fundamentales y los algoritmos de búsqueda y recorrido más usados. Tienes ahora la base conceptual con la que se construyen lenguajes, bases de datos, sistemas operativos y cualquier pieza seria de software.
El siguiente paso depende de ti: algoritmos de ordenamiento, programación dinámica, teoría de la complejidad, sistemas distribuidos, concurrencia, seguridad. Cada rama se apoya en los fundamentos que acabamos de recorrer.
Gracias por acompañarme en esta serie. Nos vemos en los próximos artículos.
BFS: búsqueda por anchura en grafos y árboles
Breadth-First Search explora nivel por nivel usando una cola. Es la base de shortest path en grafos no ponderados y del recorrido por nivele...
Recorridos de árboles: inorden, preorden y postorden explicados
Las tres formas clásicas de visitar todos los nodos de un árbol binario. Cuál usar depende del orden en que necesitas los datos. Ejemplos co...

Búsqueda binaria: cómo encontrar algo entre millones en 20 pasos
obre un array ordenado, cortar por la mitad repetidamente encuentra cualquier elemento en tiempo logarítmico. Implementación correcta y por...
Comentarios (0)
Sé el primero en comentar.
Deja un comentario