Árboles: cómo organizar datos jerárquicamente y encontrar cualquier cosa rápido
Si los arrays y las listas son estructuras lineales, los árboles son la forma natural de representar relaciones jerárquicas: carpetas anidadas, el DOM de una página web, la estructura de un documento XML, el árbol sintáctico de un programa, la jerarquía de categorías de un e-commerce, el índice de una base de datos.
Un árbol es, en esencia, una generalización de una lista enlazada: cada nodo apunta no a uno sino a varios "hijos". Esa pequeña diferencia estructural abre un mundo de algoritmos y permite búsquedas en O(log n) cuando el árbol está balanceado.
Este es el sexto artículo de Por dentro de las estructuras. Ya dominamos arrays, listas, pilas, colas y tablas hash. Nos falta entender árboles y grafos, las dos estructuras no lineales más importantes.
La idea central
Un árbol se define recursivamente:
Un árbol es un nodo con un valor y una colección (posiblemente vacía) de sub-árboles hijos.
Terminología básica:
Raíz (root): el nodo sin padre, en la cima.
Hijo / Padre: relación entre nodos adyacentes.
Hojas (leaves): nodos sin hijos.
Altura: la distancia entre la raíz y la hoja más lejana.
Profundidad de un nodo: la distancia desde la raíz hasta ese nodo.
Subárbol: cualquier nodo y todos sus descendientes.
Visualmente:
A ← raíz, profundidad 0
/ \
B C ← profundidad 1
/| |\
D E F G ← hojas, profundidad 2
En este árbol, la altura es 2, B y C son hijos de A, D y E son hijos de B, y D, E, F, G son hojas.
Árboles binarios
Un árbol binario es un árbol en el que cada nodo tiene como máximo dos hijos, normalmente llamados "izquierdo" y "derecho". Es la variante más estudiada porque simplifica algoritmos y se adapta a muchísimos problemas.
Variantes comunes:
Árbol binario completo: todos los niveles están llenos salvo quizá el último, que se llena de izquierda a derecha. Muy usados como representación implícita en heaps.
Árbol binario perfecto: todos los niveles, incluyendo el último, están completamente llenos.
Árbol binario balanceado: la altura difiere en máximo 1 entre subárboles izquierdo y derecho. Clave para mantener O(log n).
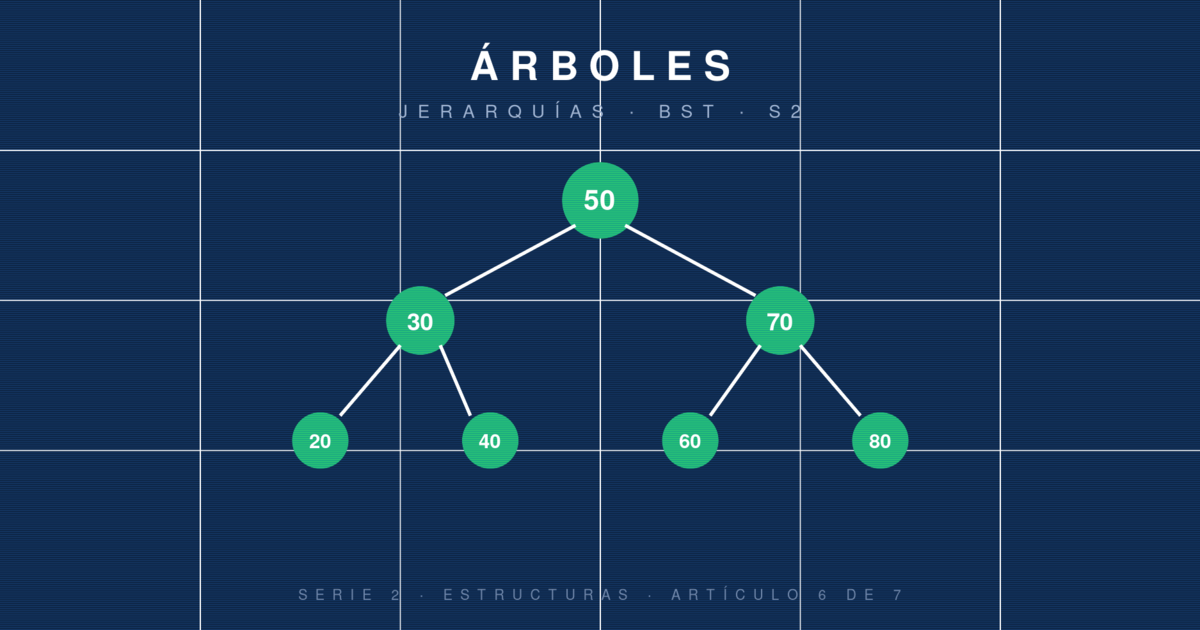
Árbol binario de búsqueda (BST): árbol binario en el que, para cada nodo, todos los valores del subárbol izquierdo son menores y todos los del derecho son mayores. Esta invariante habilita búsquedas O(log n) si está balanceado.
Árbol binario de búsqueda (BST)
El BST es la estructura jerárquica más usada en el día a día. Para insertar el valor 7 en un BST, empiezas en la raíz y decides izquierda o derecha según la comparación:
Insertar 7 en:
5
/ \
3 9
\
12
→ 7 > 5 → derecha → 9
→ 7 < 9 → izquierda → hueco → insertar aquí
Resultado:
5
/ \
3 9
/ \
7 12
Buscar el 7 sigue el mismo camino: en cada paso descartas la mitad del árbol. De ahí sale la complejidad logarítmica.
Cómo se vería en memoria
Cada nodo es un objeto en el heap con tres referencias: su valor, su hijo izquierdo y su hijo derecho.
[5 | •|• ]
/ \
[3 |nil|nil] [9 | • | • ]
/ \
[7 |nil|nil] [12 |nil|nil]
La similitud con listas enlazadas no es casual: un BST es, estructuralmente, una lista enlazada con dos punteros por nodo. Por eso comparten muchos trade-offs: flexibilidad dinámica a cambio de mala localidad de cache y overhead por nodo.
Implementación en PHP
class Nodo {
public mixed $valor;
public ?Nodo $izq = null;
public ?Nodo $der = null;
public function __construct(mixed $valor) {
$this->valor = $valor;
}
}
class BST {
private ?Nodo $raiz = null;
public function insertar(int $valor): void {
$this->raiz = $this->insertarRec($this->raiz, $valor);
}
private function insertarRec(?Nodo $nodo, int $valor): Nodo {
if ($nodo === null) return new Nodo($valor);
if ($valor < $nodo->valor) {
$nodo->izq = $this->insertarRec($nodo->izq, $valor);
} elseif ($valor > $nodo->valor) {
$nodo->der = $this->insertarRec($nodo->der, $valor);
}
return $nodo; // duplicados ignorados
}
public function buscar(int $valor): bool {
return $this->buscarRec($this->raiz, $valor);
}
private function buscarRec(?Nodo $nodo, int $valor): bool {
if ($nodo === null) return false;
if ($valor === $nodo->valor) return true;
return $valor < $nodo->valor
? $this->buscarRec($nodo->izq, $valor)
: $this->buscarRec($nodo->der, $valor);
}
}
Implementación en Java
public class BST {
static class Nodo {
int valor;
Nodo izq, der;
Nodo(int v) { this.valor = v; }
}
private Nodo raiz;
public void insertar(int v) { raiz = insertarRec(raiz, v); }
private Nodo insertarRec(Nodo n, int v) {
if (n == null) return new Nodo(v);
if (v < n.valor) n.izq = insertarRec(n.izq, v);
else if (v > n.valor) n.der = insertarRec(n.der, v);
return n;
}
public boolean buscar(int v) { return buscarRec(raiz, v); }
private boolean buscarRec(Nodo n, int v) {
if (n == null) return false;
if (v == n.valor) return true;
return v < n.valor ? buscarRec(n.izq, v) : buscarRec(n.der, v);
}
}
Eliminar en un BST
Eliminar es la operación más complicada porque hay tres casos:
Nodo hoja: simplemente apunta el padre a
null.Nodo con un hijo: apunta el padre al hijo, saltando el nodo eliminado.
Nodo con dos hijos: se sustituye por su sucesor inorden (el nodo más pequeño del subárbol derecho) y luego se elimina ese sucesor.
private Nodo eliminarRec(Nodo n, int v) {
if (n == null) return null;
if (v < n.valor) n.izq = eliminarRec(n.izq, v);
else if (v > n.valor) n.der = eliminarRec(n.der, v);
else {
// nodo encontrado
if (n.izq == null) return n.der;
if (n.der == null) return n.izq;
// dos hijos: buscar sucesor inorden
Nodo sucesor = minimoSubarbol(n.der);
n.valor = sucesor.valor;
n.der = eliminarRec(n.der, sucesor.valor);
}
return n;
}
private Nodo minimoSubarbol(Nodo n) {
while (n.izq != null) n = n.izq;
return n;
}
El problema del desbalanceo
Un BST funciona maravillosamente si está balanceado. Pero si insertamos los valores 1, 2, 3, 4, 5 en ese orden:
1
\
2
\
3
\
4
\
5
El BST se degenera en una lista enlazada. Buscar 5 ahora es O(n), no O(log n).
Por eso existen los árboles balanceados auto-organizados:
AVL: mantiene la diferencia de alturas en ≤1. Más estricto, lecturas muy rápidas.
Rojo-negro: mantiene un balance relajado. Menos operaciones de rotación, inserciones más baratas. Es lo que implementa
TreeMapyTreeSeten Java.Splay tree: auto-balancea llevando los nodos accedidos a la raíz. Bueno para patrones de acceso con localidad temporal.
Como usuario del lenguaje, rara vez implementas rotaciones a mano: usas TreeMap, TreeSet o librerías. Pero saber que están ahí por debajo te ayuda a entender por qué siguen dando O(log n) incluso con datos desordenados.
Otros tipos de árboles importantes
Heap binario: árbol completo donde cada padre es ≥ (max-heap) o ≤ (min-heap) que sus hijos. Es lo que hay detrás de
PriorityQueue.Trie: árbol donde los caminos representan cadenas. Ideal para autocompletado, diccionarios y validación de prefijos.
B-tree y B+ tree: árboles donde cada nodo tiene muchos hijos. Los usan todas las bases de datos y sistemas de archivos (MySQL InnoDB, PostgreSQL, SQLite, NTFS, ext4). La alta fanout reduce I/O de disco.
Quadtree y octree: árboles espaciales usados en gráficos 3D, videojuegos y GIS.
Suffix tree y suffix array: usados en bioinformática y búsqueda de patrones en texto.
Parse tree / AST: el compilador o intérprete usa un árbol para representar tu código.
Operaciones y su costo
Para un BST balanceado con n nodos:
OperaciónComplejidadInsertarO(log n)BuscarO(log n)EliminarO(log n)MínimoO(log n)MáximoO(log n)Recorrido completoO(n)
Para un BST desbalanceado (peor caso):
OperaciónComplejidadTodas las anterioresO(n)
En Java, TreeMap y TreeSet usan rojo-negro y garantizan O(log n) en el peor caso.
Recorridos
Un árbol se puede recorrer de muchas maneras. Las cuatro clásicas:
Inorden (izq → raíz → der): en un BST, produce los valores ordenados. Fundamental.
Preorden (raíz → izq → der): útil para copiar un árbol o serializarlo.
Postorden (izq → der → raíz): útil para liberar memoria o evaluar expresiones.
Por niveles (BFS): nivel por nivel, usa una cola.
Ejemplo en Java (recorrido inorden):
void inorden(Nodo n) {
if (n == null) return;
inorden(n.izq);
System.out.print(n.valor + " ");
inorden(n.der);
}
Los recorridos tienen su artículo propio en la Serie 3, así que ahí los detallaremos.
Ventajas y desventajas
Ventajas:
Modelan jerarquías de forma natural.
Operaciones O(log n) en balanceados: ideal para conjuntos ordenados.
Permiten recorridos que producen datos ordenados (inorden en BST).
Base de muchas estructuras más complejas (heaps, tries, B-trees).
Desventajas:
Implementar balanceo es complejo.
Cada nodo tiene overhead de punteros.
Mala localidad de cache comparado con arrays.
Si no están balanceados, degeneran a O(n).
Casos de uso reales
Índices de bases de datos: B-tree y B+ tree en MySQL, PostgreSQL, MongoDB.
Sistemas de archivos: NTFS, HFS+, ext4 usan B-tree para directorios.
Compiladores e intérpretes: parse tree y AST para representar código.
DOM: el HTML parseado es un árbol de nodos.
Autocompletado y corrector ortográfico: tries.
Routing de requests: trie de rutas para frameworks web (Laravel, Express).
Heaps para PriorityQueue: scheduling, Dijkstra, A*.
Renderizado 3D: octrees para collision detection y culling.
Git internamente: un commit es un árbol de objetos blob.
Ejemplo: índice ordenado de usuarios
Imagina un ranking de usuarios por puntaje. Con TreeMap mantenemos orden natural sin esfuerzo:
import java.util.TreeMap;
TreeMap<Integer, String> ranking = new TreeMap<>();
ranking.put(1500, "Ana");
ranking.put(900, "Bruno");
ranking.put(2300, "Clara");
ranking.put(1200, "Dante");
// firstKey(): menor, lastKey(): mayor
System.out.println("Top: " + ranking.lastEntry().getValue()); // Clara
System.out.println("Bottom: " + ranking.firstEntry().getValue()); // Bruno
// Vecinos: mejor que X, peor que X
System.out.println(ranking.higherEntry(1200)); // 1500 → Ana
System.out.println(ranking.lowerEntry(1200)); // 900 → Bruno
// SubMap: un rango completo
ranking.subMap(1000, 2000).forEach((k, v) ->
System.out.println(v + ": " + k)
);
Todas esas operaciones son O(log n). Replicar ese comportamiento con un HashMap exigiría ordenar en cada consulta.
Errores comunes
1. Insertar en un BST sin preocuparse por el orden de inserción
Si tus datos vienen ordenados y los insertas así en un BST básico, terminas con una lista enlazada. Usa TreeMap/TreeSet o inserta en orden aleatorio para mitigar.
2. Confundir árbol con BST
No todo árbol binario es un BST: la propiedad de orden (izq < nodo < der) es lo que lo hace BST. Un árbol binario genérico no tiene esa garantía.
3. Recursión profunda en árboles muy grandes
Un árbol balanceado con un millón de nodos tiene altura ~20. Uno desbalanceado tiene altura 1,000,000. La recursión naive hace stack overflow. Usa recorridos iterativos con pila explícita cuando no garantizas balanceo.
4. Modificar el árbol durante un recorrido
Igual que con mapas, modificar la estructura mientras iteras puede corromperla o lanzar ConcurrentModificationException. Acumula cambios y aplícalos al terminar.
5. Pensar que un TreeMap reemplaza a un HashMap
TreeMap es O(log n) y ordenado; HashMap es O(1) promedio y sin orden. Si no necesitas orden, HashMap es significativamente más rápido.
6. Olvidar los casos null
Cada rama recursiva debe manejar el caso base nodo == null. Olvidarlo es la causa más común de NPE en árboles.
Resumen
Un árbol es una estructura jerárquica: un nodo con subárboles hijos. Los árboles binarios limitan los hijos a 2; los BSTs añaden la propiedad de orden izq < nodo < der para búsquedas O(log n). Los árboles balanceados (AVL, rojo-negro) mantienen esa garantía incluso con inserciones en mal orden.
En Java tienes TreeMap/TreeSet para uso directo. Otras variantes como B-trees, tries, heaps y quadtrees aparecen en bases de datos, autocompletado, scheduling y gráficos 3D.
En el siguiente y último artículo de esta serie vemos los grafos, la generalización máxima: cualquier estructura que conecta cosas con cosas, desde redes sociales hasta mapas y routing de internet.
DFS: recorrido en profundidad, backtracking y la base de muchos algoritmos
Depth-First Search se sumerge hasta el fondo antes de retroceder. Usado en backtracking, detección de ciclos y ordenamiento topológico. Vers...
BFS: búsqueda por anchura en grafos y árboles
Breadth-First Search explora nivel por nivel usando una cola. Es la base de shortest path en grafos no ponderados y del recorrido por nivele...
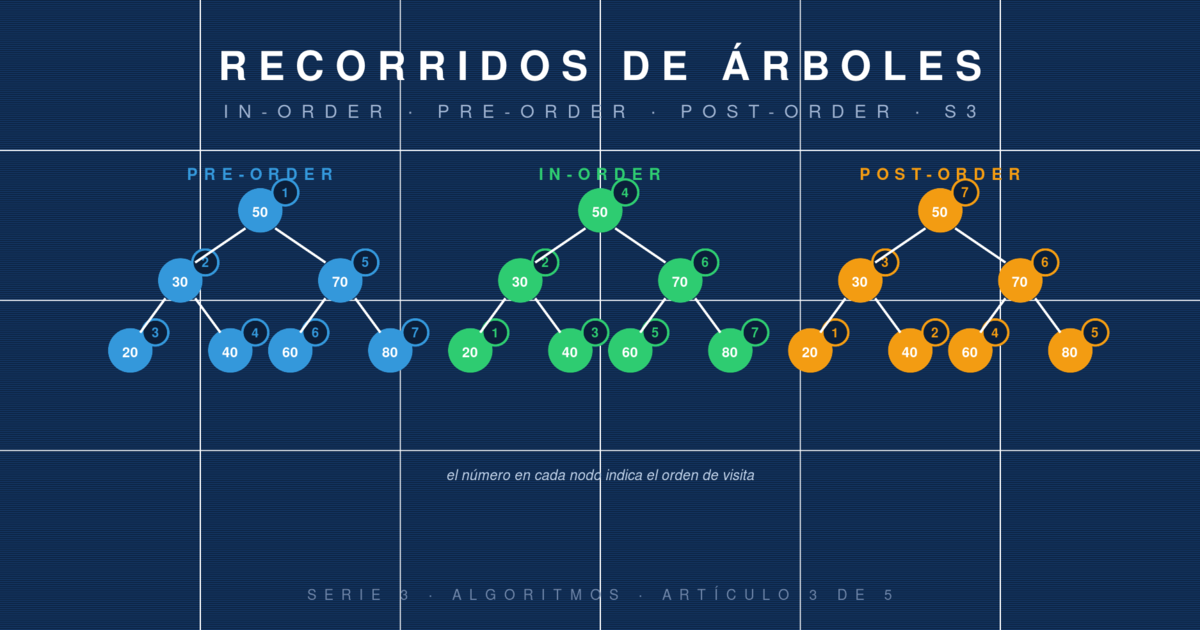
Recorridos de árboles: inorden, preorden y postorden explicados
Las tres formas clásicas de visitar todos los nodos de un árbol binario. Cuál usar depende del orden en que necesitas los datos. Ejemplos co...
Comentarios (0)
Sé el primero en comentar.
Deja un comentario