Búsqueda lineal: el algoritmo más básico que sigue siendo útil
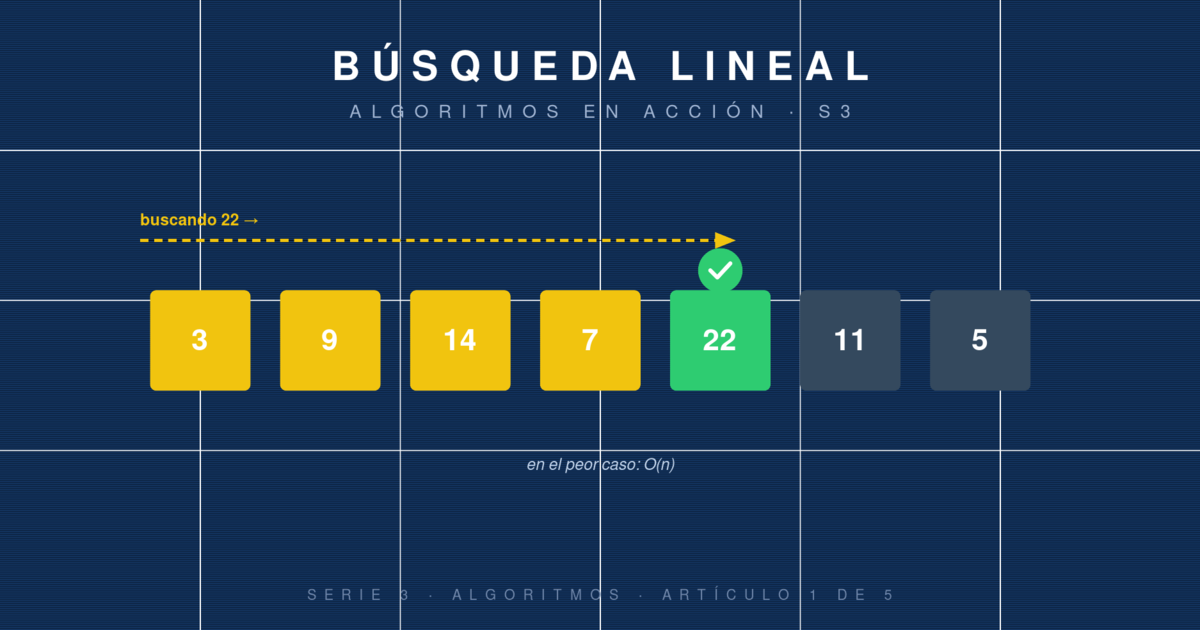
Abres una caja de calcetines desordenada y buscas el par azul marino. Sacas uno, lo miras, no es. Sacas otro, no es. Así uno a uno hasta encontrarlo. Acabas de ejecutar, sin saberlo, una búsqueda lineal: el algoritmo más simple para encontrar un elemento en una colección, y muy a menudo, el único que puedes aplicar.
Este artículo abre la Serie 3, Cómo se busca y se recorre. Aquí nos enfocamos en algoritmos que operan sobre las estructuras de datos que ya estudiamos en la Serie 2. Empezamos por el más humilde y universal.
La idea central
La búsqueda lineal consiste en:
Recorrer la colección elemento por elemento, desde el inicio hasta el final.
Comparar cada elemento con el objetivo.
Si se encuentra, devolver su posición (o
true). Si se llega al final sin encontrarlo, devolver-1(ofalse).
No requiere que la colección esté ordenada ni tenga índice alguno. Por eso es universal: funciona sobre cualquier array, lista enlazada, cola, pila o iterable.
Cómo se vería en memoria
Imagina un array [4, 7, 2, 9, 3, 6] y queremos buscar el 9:
paso 1: arr[0] = 4 != 9
paso 2: arr[1] = 7 != 9
paso 3: arr[2] = 2 != 9
paso 4: arr[3] = 9 == 9 ← ¡encontrado!
En total, 4 comparaciones. En el peor caso (elemento al final o no presente), serían 6.
Implementación en PHP
function busquedaLineal(array $arr, mixed $objetivo): int {
foreach ($arr as $indice => $valor) {
if ($valor === $objetivo) {
return $indice;
}
}
return -1;
}
echo busquedaLineal([4, 7, 2, 9, 3, 6], 9); // 3
echo busquedaLineal([4, 7, 2, 9, 3, 6], 1); // -1
PHP ya trae funciones nativas para esto: array_search devuelve la llave o false, y in_array devuelve un booleano. Ambas hacen búsqueda lineal por debajo:
$indice = array_search(9, [4, 7, 2, 9, 3, 6]); // 3
$existe = in_array(9, [4, 7, 2, 9, 3, 6]); // true
Cuidado con la comparación por defecto, que usa == (suelto); si quieres comparación estricta pasa true como tercer argumento:
in_array("9", [4, 7, 2, 9, 3, 6], true); // false
Implementación en Java
public static <T> int busquedaLineal(T[] arr, T objetivo) {
for (int i = 0; i < arr.length; i++) {
if (Objects.equals(arr[i], objetivo)) {
return i;
}
}
return -1;
}
Java tiene utilidades en Arrays y Collections:
int[] nums = {4, 7, 2, 9, 3, 6};
// Opción 1: IntStream
int indice = IntStream.range(0, nums.length)
.filter(i -> nums[i] == 9)
.findFirst()
.orElse(-1);
// Opción 2: List
List<Integer> lista = List.of(4, 7, 2, 9, 3, 6);
int indice2 = lista.indexOf(9); // 3
boolean existe = lista.contains(9); // true
indexOf y contains en ArrayList son búsqueda lineal O(n). En HashSet o HashMap son O(1) porque usan hash.
Complejidad
EscenarioTiempoMejor caso (primer elemento)O(1)Caso promedioO(n/2) = O(n)Peor caso (último o no presente)O(n)EspacioO(1)
Para un array de un millón de elementos, el peor caso son un millón de comparaciones. En un procesador moderno, eso son unos pocos milisegundos si el array cabe en RAM y tiene buena localidad de cache. Esa velocidad es parte de por qué, para tamaños pequeños, la búsqueda lineal vence en la práctica a algoritmos más sofisticados.
¿Cuándo es realmente la opción correcta?
Aunque O(n) suene mal, hay muchos escenarios donde la búsqueda lineal es lo óptimo o lo único viable:
1. Colecciones pequeñas
Si tu lista tiene menos de ~50 elementos, el overhead de una estructura más compleja (hash, árbol) suele ser mayor que recorrer linealmente. Las CPUs modernas son buenísimas ejecutando bucles contiguos.
2. Datos no ordenables
Si los elementos no tienen un orden natural y no podés calcular un hash razonable, buscar linealmente es todo lo que tenés.
3. Una búsqueda puntual sobre datos que cambian todo el tiempo
Construir un índice (hash, árbol) tiene costo. Si vas a buscar una sola vez y la colección cambia continuamente, no vale la pena mantener el índice.
4. Búsqueda con condición compleja
Si buscas "el primer usuario cuyo nombre empiece con 'A' y tenga más de 30 años y viva en CDMX", no hay índice precalculado que te sirva. La búsqueda lineal con un predicado compuesto es la solución natural.
Optional<Usuario> u = usuarios.stream()
.filter(x -> x.nombre.startsWith("A") && x.edad > 30 && "CDMX".equals(x.ciudad))
.findFirst();
5. Iterables sin acceso aleatorio
Si estás leyendo de un stream, un cursor de base de datos, un archivo línea por línea, no tenés acceso aleatorio. Solo podés recorrer: lineal.
Optimizaciones clásicas
Algunas variantes aumentan ligeramente la eficiencia en casos específicos:
Búsqueda con centinela
En lenguajes de bajo nivel, poner el objetivo al final del array para evitar el check de límites:
arr[n] = objetivo; // centinela
i = 0;
while arr[i] != objetivo: i++;
if i < n: encontrado en i
Ahorra una comparación por iteración. En Java y PHP no vale la pena porque el JIT y la función nativa lo optimizan mejor.
Early exit con predicados múltiples
Ordena los predicados de más a menos selectivos (rápidos y que descarten más). Así, al combinar con AND, el primero que falle corta la evaluación:
.filter(x -> x.edad > 30 // descarta mucho
&& x.nombre.startsWith("A") // descarta bastante
&& "CDMX".equals(x.ciudad)) // descarta poco
Transposición / move-to-front
Cada vez que encuentras un elemento, muévelo al inicio. Si el patrón de búsqueda es muy sesgado (80/20), las búsquedas futuras son más baratas. Se usa en caches sencillos.
Ventajas y desventajas
Ventajas:
Simple de implementar y de entender.
Funciona sobre cualquier colección iterable.
No requiere ordenamiento ni estructuras auxiliares.
Muy rápida para n pequeño o cuando el elemento está al principio.
Desventajas:
O(n) en el peor caso.
Para colecciones grandes y búsquedas frecuentes, mucho peor que índice hash o búsqueda binaria.
Casos de uso reales
Recorrer una configuración en memoria con 20 entradas.
Buscar en resultados paginados ya cargados en frontend.
Primera coincidencia en un stream de logs.
Implementaciones internas de
contains/indexOfenArrayListyLinkedList.Validaciones sobre listas pequeñas de exclusiones (blacklists cortas, feature flags).
Listas de suscriptores a un evento en un EventBus o observer pattern.
Cuándo conviene migrar a algo mejor
Si detectas que:
La colección es grande (>1000 elementos) y
Haces búsquedas frecuentes, y
El coste dominante de tu aplicación es justamente esa búsqueda,
entonces conviene migrar a:
Hash: si solo buscas por igualdad exacta de llave. O(1) promedio.
Búsqueda binaria: si la colección se puede mantener ordenada. O(log n). La vemos en el siguiente artículo.
TreeMap/TreeSet: si necesitas ordenación + búsqueda + rangos. O(log n).
Índice invertido: si buscas por múltiples atributos o por texto.
Errores comunes
1. Usar búsqueda lineal dentro de un bucle O(n)
for (Usuario u : lista1) {
if (lista2.contains(u.id)) { ... } // contains es O(n)
}
Si lista2.contains es O(n), el total es O(n²). Convierte lista2 a un HashSet una sola vez antes del bucle.
2. Comparar con == en lugar de equals en Java
Para objetos, == compara referencias. Usa Objects.equals o el método equals explícito.
3. No manejar el caso no encontrado
Olvidar el return -1 o devolver 0 (que es un índice válido) confunde al llamante. Define el contrato y respétalo.
4. Buscar en una lista enlazada sin darse cuenta
Un LinkedList.get(i) parece O(1) pero internamente recorre los nodos: O(n). Hacer búsqueda lineal sobre una LinkedList tiene tuercas ocultas de overhead por punteros; si puedes, migra a ArrayList para datos que solo vas a recorrer.
5. Asumir orden
Si la búsqueda lineal se detiene cuando valor >= objetivo, solo funciona si el array está ordenado. Si no lo está, puedes devolver "no encontrado" para algo que sí estaba.
Resumen
La búsqueda lineal recorre la colección elemento por elemento hasta encontrar el objetivo o agotarla. Es O(n), simple, universal, y perfectamente razonable para colecciones pequeñas, iterables sin acceso aleatorio, predicados complejos o búsquedas puntuales.
Para colecciones grandes con muchas búsquedas, migra a hash (O(1)) o a binaria (O(log n)). En el siguiente artículo vemos búsqueda binaria, el algoritmo estrella para arrays ordenados.
DFS: recorrido en profundidad, backtracking y la base de muchos algoritmos
Depth-First Search se sumerge hasta el fondo antes de retroceder. Usado en backtracking, detección de ciclos y ordenamiento topológico. Vers...
BFS: búsqueda por anchura en grafos y árboles
Breadth-First Search explora nivel por nivel usando una cola. Es la base de shortest path en grafos no ponderados y del recorrido por nivele...
Recorridos de árboles: inorden, preorden y postorden explicados
Las tres formas clásicas de visitar todos los nodos de un árbol binario. Cuál usar depende del orden en que necesitas los datos. Ejemplos co...
Comentarios (0)
Sé el primero en comentar.
Deja un comentario