Complejidad algorítmica: cómo se mide qué tan rápido es tu código
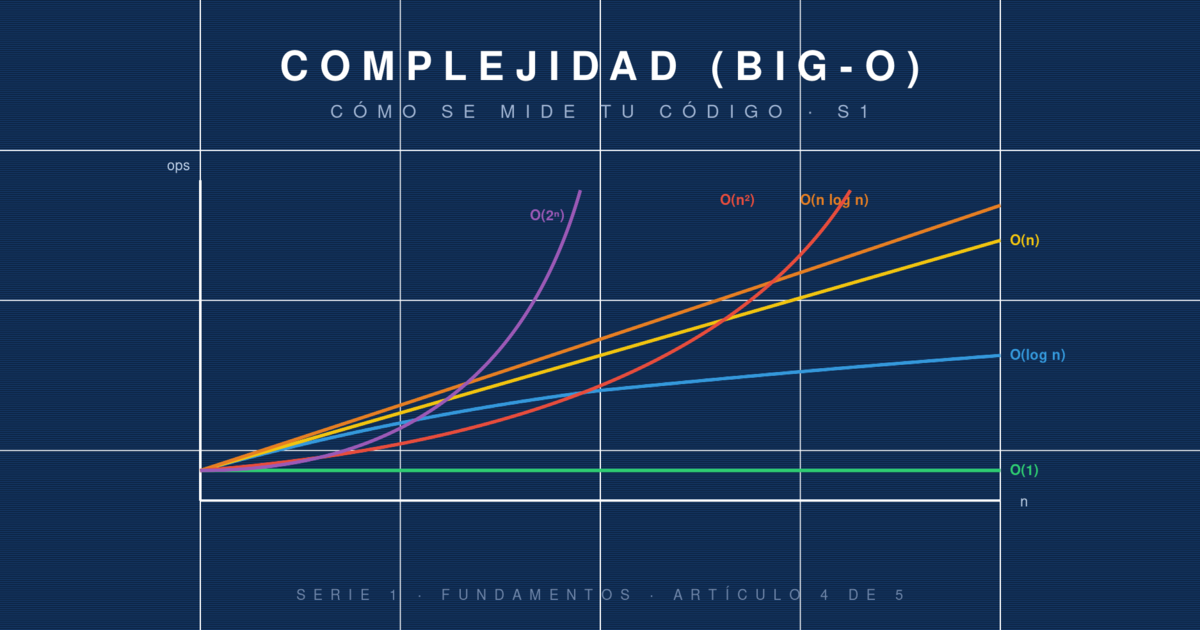
"Este código es lento" es una frase subjetiva. Depende del hardware, del lenguaje, de la carga del servidor, de si tu laptop tiene 8 o 32 GB de RAM. Para discutir el rendimiento de un algoritmo con precisión, la industria adoptó una notación que elimina todas esas variables: la notación Big-O.
Big-O mide cómo crece el número de operaciones (o la memoria usada) en función del tamaño de la entrada. No dice cuánto tarda en milisegundos, dice cómo se comporta cuando los datos crecen. Con eso basta para tomar decisiones de arquitectura que se mantienen válidas en cualquier máquina.
Este artículo es el cuarto de la serie Pensar como la máquina. En los tres anteriores vimos iteración, recursión y recursión de cola. Big-O es la herramienta que usas para evaluar cualquiera de ellas.
La idea central, en una frase
Big-O describe el peor caso del crecimiento asintótico de un algoritmo. "Asintótico" significa: cuando el tamaño de la entrada tiende a infinito, ¿qué función describe aproximadamente el número de operaciones?
Si un algoritmo hace 3n + 5 operaciones para una entrada de tamaño n, Big-O dice que es O(n): se ignoran las constantes y los términos menores, porque cuando n es grande, lo único que importa es el término dominante.
Las clases más comunes, ordenadas de mejor a peor:
O(1) ← constante: no depende de n
O(log n) ← logarítmica: búsqueda binaria
O(n) ← lineal: recorrer una colección
O(n log n) ← linearítmica: mergesort, quicksort
O(n²) ← cuadrática: bucles anidados
O(2ⁿ) ← exponencial: fuerza bruta sobre subconjuntos
O(n!) ← factorial: generar todas las permutaciones
Para que te sitúes: con n = 1,000,000, un algoritmo O(log n) hace ~20 operaciones, uno O(n) hace un millón, uno O(n²) hace un billón (y tarda horas), uno O(2ⁿ) ni vale la pena calcularlo.
Cómo se calcula en código real
La regla práctica: cuenta las operaciones básicas (comparaciones, asignaciones, accesos a memoria) y expresa el total como función de n. Luego quédate solo con el término dominante y descarta constantes.
O(1) — acceso por índice
function primero(array $arr): int {
return $arr[0];
}
Independientemente de si el array tiene 10 o 10 millones de elementos, esto hace una sola operación. Costo: O(1).
O(n) — recorrer una colección
int suma(int[] arr) {
int total = 0;
for (int n : arr) {
total += n;
}
return total;
}
Si el array tiene n elementos, el bucle ejecuta n iteraciones. Costo: O(n).
O(n²) — bucles anidados
boolean tieneDuplicados(int[] arr) {
for (int i = 0; i < arr.length; i++) {
for (int j = i + 1; j < arr.length; j++) {
if (arr[i] == arr[j]) return true;
}
}
return false;
}
El bucle externo se ejecuta n veces; por cada iteración, el interno hace hasta n iteraciones. Total: ~n²/2 comparaciones. Costo: O(n²).
O(log n) — dividir a la mitad en cada paso
int busquedaBinaria(int[] arr, int target) {
int low = 0, high = arr.length - 1;
while (low <= high) {
int mid = low + (high - low) / 2;
if (arr[mid] == target) return mid;
if (arr[mid] < target) low = mid + 1;
else high = mid - 1;
}
return -1;
}
Cada iteración reduce a la mitad el espacio de búsqueda. Si empiezas con un array de n elementos, en cuántos pasos lo reduces a 1? La respuesta es log₂(n). Costo: O(log n).
Reglas prácticas para analizar tu propio código
1. Un bucle sobre n elementos es O(n)
Si recorres la entrada una vez, lineal.
2. Dos bucles anidados sobre n son O(n²)
Por cada iteración del externo, el interno completa. Si los dos recorren la misma estructura, el costo es n·n = n².
3. Bucles sucesivos (no anidados) se suman, no se multiplican
for (int x : arr) a(x); // O(n)
for (int x : arr) b(x); // O(n)
// Total: O(n) + O(n) = O(2n) = O(n)
Big-O descarta constantes. O(2n) se escribe como O(n).
4. Operaciones dentro de un bucle se multiplican por el número de iteraciones
Si dentro de un bucle O(n) llamas a una función O(log n), el total es O(n log n).
for (int x : arr) { // n iteraciones
busquedaBinaria(otroArr, x); // O(log n) cada una
}
// Total: O(n log n)
5. Solo importa el término dominante
O(n² + n) se escribe O(n²). Para n grande, el término cuadrático aplasta al lineal.
Complejidad espacial
Hasta aquí hablamos de tiempo (operaciones), pero el mismo análisis aplica a memoria. La pregunta es: ¿cuánta memoria adicional requiere el algoritmo en función del tamaño de la entrada?
O(1) espacio: el algoritmo usa una cantidad fija de memoria (unos pocos contadores). Ejemplo: búsqueda lineal, búsqueda binaria iterativa.
O(n) espacio: el algoritmo usa memoria proporcional a la entrada. Ejemplo: copiar un array, o una recursión con profundidad n que abre un stack frame por nivel.
O(log n) espacio: recursiones que dividen a la mitad, como búsqueda binaria recursiva o mergesort.
Este análisis es crítico cuando trabajas con datasets grandes: un algoritmo O(n log n) en tiempo pero O(n) en memoria puede ser inviable si tu n es un billón de registros.
Peor caso, caso promedio y caso mejor
Big-O formalmente describe el peor caso, pero hay notaciones hermanas:
O (Big-O): cota superior. El algoritmo nunca es peor que esto.
Ω (Big-Omega): cota inferior. El algoritmo nunca es mejor que esto.
Θ (Big-Theta): cota ajustada. El algoritmo es exactamente de este orden.
En el uso cotidiano, cuando decimos "Big-O" casi siempre nos referimos a Θ: el orden de crecimiento real del algoritmo en el peor caso. Las distinciones formales se ven en cursos universitarios; en el día a día, si dices "HashMap es O(1) en promedio" todos te entienden.
Algunos órdenes comunes en estructuras que veremos después
Aquí adelantamos la tabla que vamos a ir llenando artículo por artículo en la Serie 2: Por dentro de las estructuras. Es útil tenerla como referencia:
EstructuraAccesoBúsquedaInserciónEliminaciónArrayO(1)O(n)O(n)O(n)Array ordenadoO(1)O(log n)O(n)O(n)Lista enlazadaO(n)O(n)O(1) al inicioO(1) si tienes el nodoPila——O(1)O(1)Cola——O(1)O(1)Tabla hash—O(1) prom.O(1) prom.O(1) prom.BST balanceadoO(log n)O(log n)O(log n)O(log n)
La tabla cambia según la implementación exacta (por ejemplo, un HashMap degenera a O(n) si la función hash es pésima), pero como referencia inicial te sirve.
Errores comunes
1. Confundir peor caso con caso promedio
HashMap es O(1) en promedio, pero O(n) en el peor caso (todas las llaves colisionando). Cuando diseñas un sistema crítico, preguntar solo por el promedio es peligroso: bajo ciertas condiciones adversariales (un atacante que manda llaves colisionantes a propósito), el peor caso aparece.
2. Ignorar las constantes ocultas en problemas pequeños
Big-O es asintótico: describe el comportamiento cuando n tiende a infinito. Para n pequeño, las constantes pueden dominar. Un algoritmo O(n²) con constante pequeña puede ser más rápido que uno O(n log n) con constante enorme, hasta cierto n. Ejemplo: el ordenamiento por inserción vence a quicksort en arrays de menos de ~10 elementos. Muchas librerías combinan ambos por esta razón.
3. Comparar Big-O sin ejecutar el código
La notación es una herramienta, no un oráculo. Dos algoritmos O(n log n) pueden tener factores constantes muy distintos. El cache de CPU, las predicciones de branch, la localidad de memoria afectan enormemente al tiempo real. Mide. Siempre mide.
4. Olvidar que "operación" es elástico
Cuando decimos "el acceso a un HashMap es O(1)", estamos asumiendo que calcular el hash es O(1). Para llaves de string largas, el hash es O(k) donde k es la longitud del string. Técnicamente, HashMap de strings largos es O(k) amortizado, no O(1).
5. Pensar que Big-O es solo para entrevistas
Es un error muy común. La realidad es que elegir entre un array y una tabla hash basándose en los patrones de acceso, o entre mergesort y radixsort según el tipo de dato, son decisiones del día a día que dependen de Big-O. Cuando un sistema se cae porque crece 10× y el tiempo se multiplicó por 100, casi siempre es un problema de complejidad.
Un consejo pragmático
Cuando analices tu propio código, sigue este protocolo:
Identifica el tamaño de la entrada (
n,m,k). A veces hay varios.Cuenta los bucles y su profundidad.
Identifica las llamadas a funciones dentro de los bucles y añade su costo.
Suma y quédate con el término dominante, descarta constantes.
Si el resultado te asusta, busca reducirlo. Normalmente las herramientas son: cambiar de estructura de datos (pasar de lista a hash), ordenar antes de buscar, dividir y vencerás, o memoización.
Resumen
Big-O describe cómo crece el costo de un algoritmo —en tiempo o memoria— cuando la entrada crece. Las clases comunes son O(1), O(log n), O(n), O(n log n), O(n²) y O(2ⁿ). Solo importa el término dominante y se descartan constantes.
El análisis práctico se hace contando bucles, anidamientos y llamadas a funciones. Big-O te permite comparar algoritmos sin importar el hardware, pero conviene siempre medir para validar.
En el siguiente artículo de la serie completamos el terreno mental con los dos tipos de memoria que usa todo programa: stack y heap. Después de eso arrancamos con las estructuras de datos.
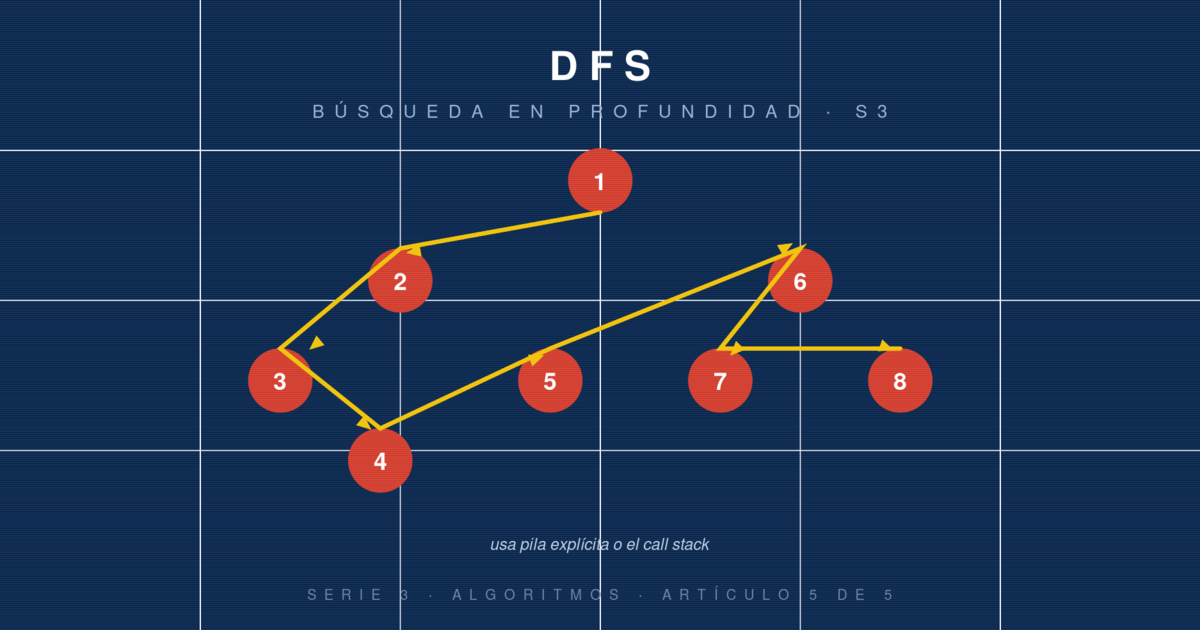
DFS: recorrido en profundidad, backtracking y la base de muchos algoritmos
Depth-First Search se sumerge hasta el fondo antes de retroceder. Usado en backtracking, detección de ciclos y ordenamiento topológico. Vers...
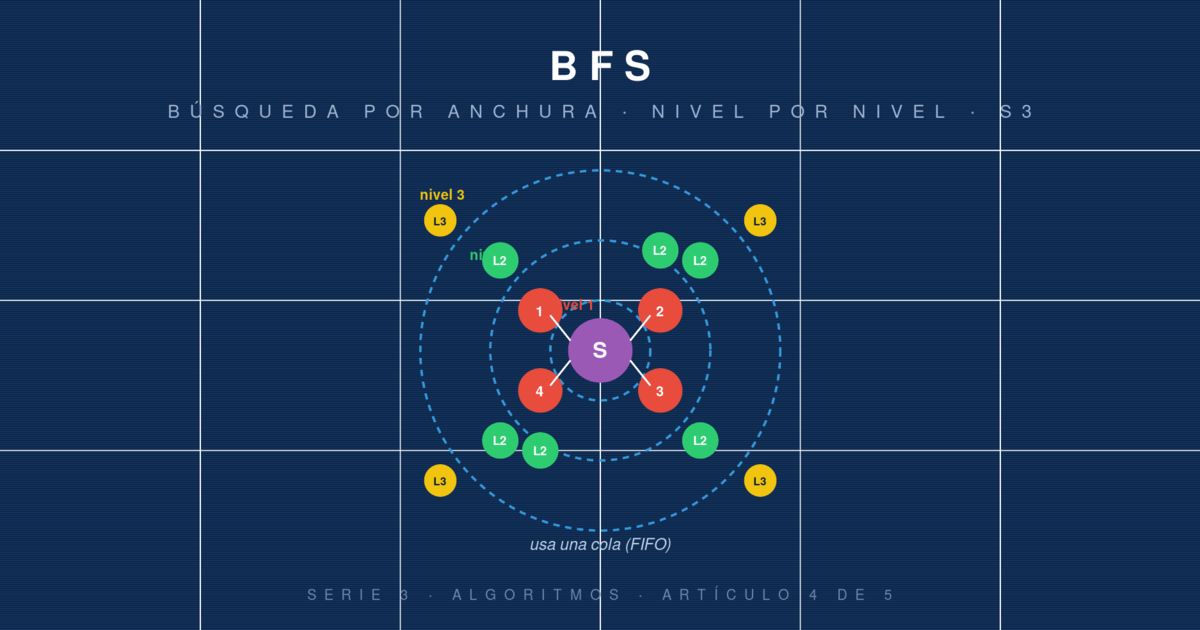
BFS: búsqueda por anchura en grafos y árboles
Breadth-First Search explora nivel por nivel usando una cola. Es la base de shortest path en grafos no ponderados y del recorrido por nivele...
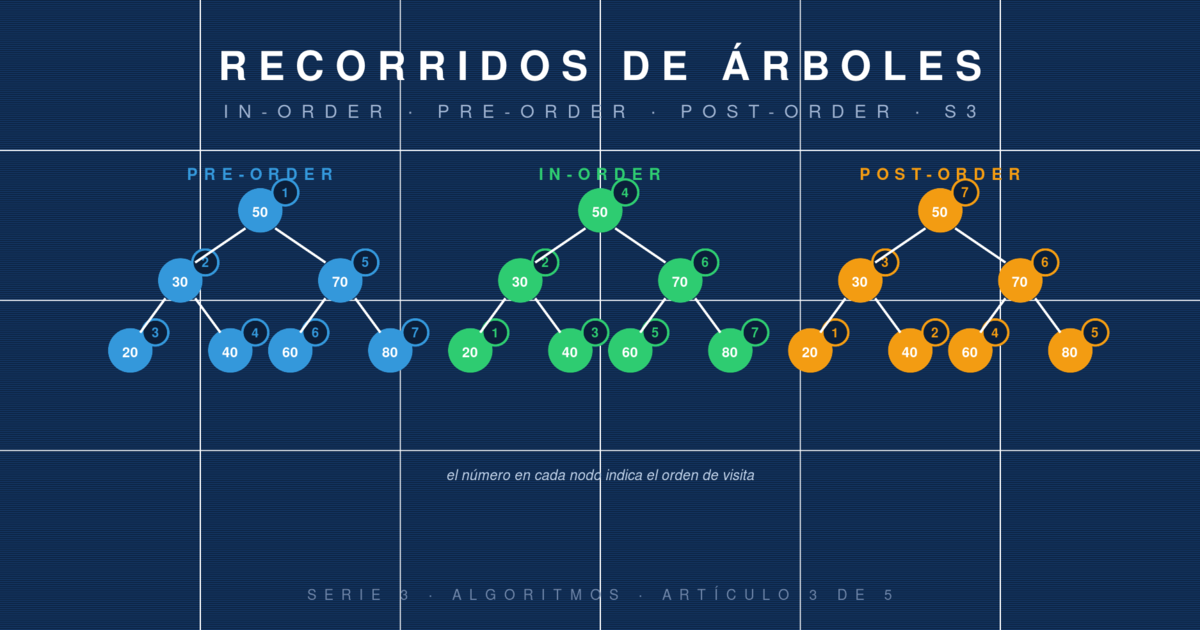
Recorridos de árboles: inorden, preorden y postorden explicados
Las tres formas clásicas de visitar todos los nodos de un árbol binario. Cuál usar depende del orden en que necesitas los datos. Ejemplos co...
Comentarios (0)
Sé el primero en comentar.
Deja un comentario