Grafos: modelar relaciones en tu código
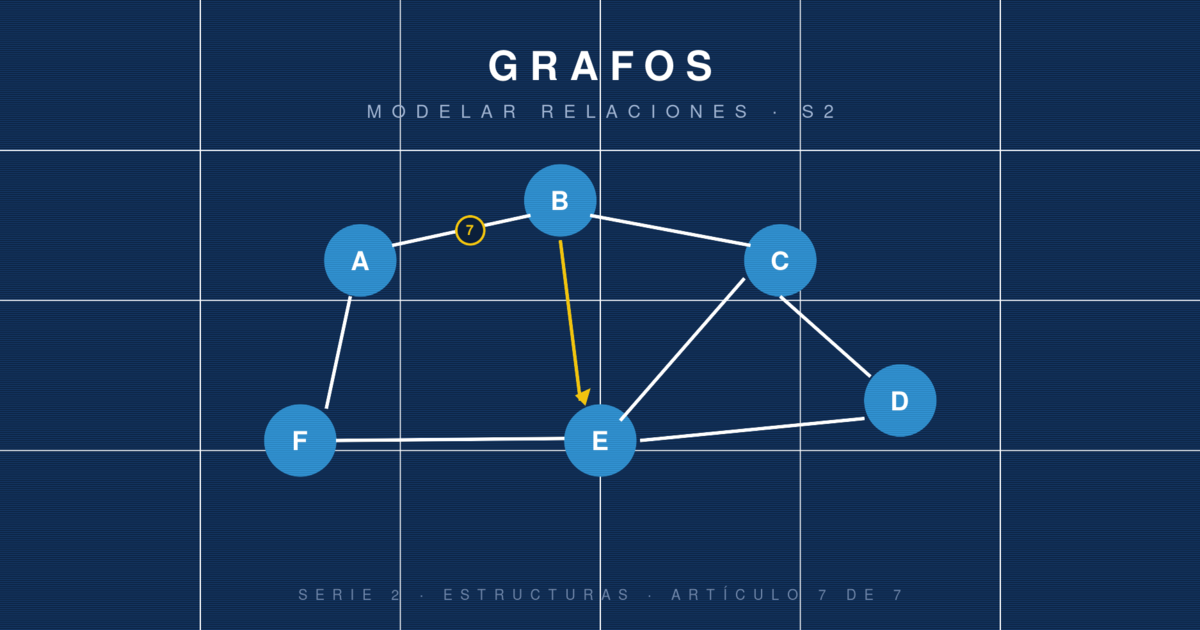
Si los árboles son jerarquías con una raíz única, los grafos son relaciones generales entre entidades. Una red social donde las personas se conectan en cualquier dirección es un grafo. Google Maps, con ciudades y carreteras, es un grafo. Las dependencias entre paquetes de npm, las menciones entre páginas web, los enlaces de hipertexto, las rutas de aviones, las compras en un e-commerce, los tuits y los retuits, las transacciones bancarias: todo grafos.
Son probablemente la estructura de datos más general: un árbol es un grafo sin ciclos, una lista enlazada es un grafo muy delgado, un heap es un grafo con reglas adicionales. Saber pensar en grafos es una habilidad que se amortiza durante toda la carrera profesional.
Este es el séptimo y último artículo de la serie Por dentro de las estructuras.
La idea central
Un grafo se compone de:
Vértices (o nodos): las entidades. Personas, ciudades, paquetes, transacciones.
Aristas (o enlaces, edges): las relaciones entre ellas. Amistad, carretera, dependencia, pago.
Formalmente, un grafo G es un par (V, E) donde V es el conjunto de vértices y E ⊆ V × V es el conjunto de aristas.
Variantes importantes:
Dirigido / no dirigido: ¿las aristas tienen sentido? Twitter es dirigido ("A sigue a B" no implica "B sigue a A"); Facebook clásico no dirigido (la amistad es mutua).
Ponderado / sin ponderar: ¿las aristas tienen peso? Un mapa con distancias es ponderado; una red social de "sí/no es amigo" no.
Cíclico / acíclico: ¿hay ciclos? Un árbol es acíclico; la mayoría de grafos reales son cíclicos.
Conexo / disconexo: ¿se puede llegar de cualquier vértice a cualquier otro? En un grafo disconexo hay componentes aisladas.
Denso / disperso: ¿hay muchas aristas respecto al máximo posible?
Cómo se vería en memoria
Hay dos formas principales de representar un grafo.
Matriz de adyacencia
Una matriz n × n donde A[i][j] = 1 si hay arista del vértice i al j, y 0 si no. Si es ponderado, guardamos el peso en lugar de 1.
Para el grafo:
0 ←→ 1
↕ ↓
2 ←→ 3
La matriz sería (suponiendo no dirigido):
0 1 2 3
0 [0, 1, 1, 0]
1 [1, 0, 0, 1]
2 [1, 0, 0, 1]
3 [0, 1, 1, 0]
Ventajas: consultar si existe la arista (i, j) es O(1). Matemáticas rápidas (multiplicar matrices para caminos de longitud k, por ejemplo).
Desventajas: consume O(n²) memoria incluso si hay pocas aristas. Para un grafo con un millón de nodos y pocos enlaces (típico en redes sociales), es inviable.
Lista de adyacencia
Para cada vértice, mantenemos una lista con sus vecinos:
0: [1, 2]
1: [0, 3]
2: [0, 3]
3: [1, 2]
En código, suele ser un Map<Vertice, List<Vertice>> o un array de listas.
Ventajas: memoria proporcional al número de aristas, O(V + E). Mucho mejor para grafos dispersos (la mayoría en la práctica).
Desventajas: consultar si existe la arista (i, j) es O(grado del vértice i). Iterar vecinos es O(grado).
Regla práctica: casi siempre usa lista de adyacencia. Matriz de adyacencia solo si el grafo es muy denso (E ~ V²) o si necesitas operaciones matriciales.
Implementación en PHP
class Grafo {
// adyacencia: vertice => lista de vertices vecinos
private array $adyacencia = [];
public function agregarVertice(string $v): void {
if (!isset($this->adyacencia[$v])) {
$this->adyacencia[$v] = [];
}
}
public function agregarArista(string $u, string $v, bool $dirigido = false): void {
$this->agregarVertice($u);
$this->agregarVertice($v);
$this->adyacencia[$u][] = $v;
if (!$dirigido) {
$this->adyacencia[$v][] = $u;
}
}
public function vecinos(string $v): array {
return $this->adyacencia[$v] ?? [];
}
public function vertices(): array {
return array_keys($this->adyacencia);
}
}
$g = new Grafo();
$g->agregarArista("Ana", "Bruno");
$g->agregarArista("Ana", "Clara");
$g->agregarArista("Bruno", "Dante");
print_r($g->vecinos("Ana")); // [Bruno, Clara]
Implementación en Java
import java.util.*;
public class Grafo<T> {
private final Map<T, List<T>> adyacencia = new HashMap<>();
private final boolean dirigido;
public Grafo(boolean dirigido) { this.dirigido = dirigido; }
public void agregarVertice(T v) {
adyacencia.putIfAbsent(v, new ArrayList<>());
}
public void agregarArista(T u, T v) {
agregarVertice(u);
agregarVertice(v);
adyacencia.get(u).add(v);
if (!dirigido) adyacencia.get(v).add(u);
}
public List<T> vecinos(T v) {
return adyacencia.getOrDefault(v, List.of());
}
public Set<T> vertices() { return adyacencia.keySet(); }
}
Para un grafo ponderado, cambia List<T> por List<Arista<T>> donde Arista tiene destino y peso:
record Arista<T>(T destino, double peso) {}
Map<T, List<Arista<T>>> adyacencia = new HashMap<>();
Operaciones y su costo
Con V vértices y E aristas:
OperaciónMatriz adyacenciaLista adyacenciaAgregar vérticeO(V²)O(1)Agregar aristaO(1)O(1)Eliminar aristaO(1)O(grado)¿Existe arista (u,v)?O(1)O(grado u)Iterar vecinos de vO(V)O(grado v)EspacioO(V²)O(V + E)
Para algoritmos clásicos sobre lista de adyacencia: BFS y DFS son O(V + E); Dijkstra con priority queue es O((V + E) log V); Bellman-Ford es O(V·E); Floyd-Warshall es O(V³).
Recorridos: BFS y DFS
Los dos recorridos fundamentales en grafos son:
BFS (Breadth-First Search): explora nivel por nivel desde un origen, usando una cola. Útil para encontrar el camino más corto en grafos sin peso.
DFS (Depth-First Search): explora tan profundo como puede antes de retroceder, usando pila explícita o recursión. Útil para ordenamiento topológico, detección de ciclos, componentes conexas, problemas de backtracking.
Los cubrimos en detalle en los artículos 4 y 5 de la Serie 3, pero aquí va el esqueleto:
BFS
public List<T> bfs(T origen) {
List<T> orden = new ArrayList<>();
Set<T> visitados = new HashSet<>();
Queue<T> cola = new ArrayDeque<>();
cola.offer(origen);
visitados.add(origen);
while (!cola.isEmpty()) {
T v = cola.poll();
orden.add(v);
for (T vecino : vecinos(v)) {
if (visitados.add(vecino)) cola.offer(vecino);
}
}
return orden;
}
DFS (iterativo con pila)
public List<T> dfs(T origen) {
List<T> orden = new ArrayList<>();
Set<T> visitados = new HashSet<>();
Deque<T> pila = new ArrayDeque<>();
pila.push(origen);
while (!pila.isEmpty()) {
T v = pila.pop();
if (visitados.add(v)) {
orden.add(v);
for (T vecino : vecinos(v)) {
if (!visitados.contains(vecino)) pila.push(vecino);
}
}
}
return orden;
}
Misma complejidad, comportamiento distinto.
Algoritmos clásicos sobre grafos
Solo menciono los que suelen aparecer en entrevistas y en proyectos reales; cada uno merece su propio artículo:
Dijkstra: camino más corto desde un origen, con pesos no negativos. Usa priority queue. O((V + E) log V).
Bellman-Ford: camino más corto con pesos negativos permitidos. O(V·E). Detecta ciclos negativos.
Floyd-Warshall: todos los pares de caminos más cortos. O(V³).
A*: dijkstra + heurística, para pathfinding en mapas y videojuegos.
Kruskal y Prim: árbol de expansión mínima (minimum spanning tree).
Kahn / DFS topológico: ordenamiento topológico en DAGs, base de schedulers de tareas, build systems y compiladores.
Tarjan / Kosaraju: componentes fuertemente conexas en grafos dirigidos.
Ford-Fulkerson / Edmonds-Karp: flujo máximo.
PageRank: importancia de nodos en un grafo dirigido (Google usaba esto).
Ventajas y desventajas
Ventajas:
Generalidad: modelan cualquier relación entre entidades.
Base de algoritmos potentes (rutas, matching, recomendación, flujo).
Lista de adyacencia es memory-friendly para grafos dispersos.
Desventajas:
La elección de representación (matriz vs lista) es un compromiso con consecuencias serias.
Muchos problemas sobre grafos son NP-duros (TSP, clique máximo, coloring). Hay que conocer heurísticas.
Mala localidad de cache; cada salto a un vecino puede ser un cache miss.
Grafos gigantes (cientos de millones de aristas) necesitan bases de datos especializadas: Neo4j, DGraph, Amazon Neptune.
Casos de uso reales
Redes sociales: Facebook, LinkedIn, Twitter. "Amigos en común", "A quién seguir", detección de comunidades.
Rutas y navegación: Google Maps, Waze. Dijkstra y A* sobre grafos ponderados donde los pesos son tiempo, distancia, tráfico.
Internet y routing: protocolos como OSPF y BGP calculan caminos sobre el grafo de routers.
Recomendaciones: "La gente que compró X también compró Y" se modela como un grafo bipartito usuarios-productos.
Detección de fraude: grafos de transacciones bancarias donde patrones anómalos (ciclos, hubs sospechosos) sugieren fraude.
Build systems y dependencias: Maven, Gradle, npm, pip ordenan topológicamente el grafo de dependencias.
Git: el historial de commits es un DAG (grafo acíclico dirigido).
Compiladores: grafos de control de flujo (CFG), call graphs, def-use graphs.
Epidemiología: modelado de propagación de enfermedades.
Knowledge graphs: Wikidata, Google Knowledge Graph, ontologías.
Ejemplo completo: grados de separación
Este es un problema clásico: dadas dos personas en una red social, ¿cuál es la distancia mínima entre ellas? La respuesta es BFS sobre el grafo de amistades.
public int gradosDeSeparacion(T origen, T destino) {
if (origen.equals(destino)) return 0;
Map<T, Integer> distancia = new HashMap<>();
distancia.put(origen, 0);
Queue<T> cola = new ArrayDeque<>();
cola.offer(origen);
while (!cola.isEmpty()) {
T v = cola.poll();
for (T vecino : vecinos(v)) {
if (!distancia.containsKey(vecino)) {
distancia.put(vecino, distancia.get(v) + 1);
if (vecino.equals(destino)) return distancia.get(vecino);
cola.offer(vecino);
}
}
}
return -1; // no conectados
}
Con este algoritmo y un grafo modesto, se puede demostrar la famosa teoría de los "seis grados de separación".
Errores comunes
1. Usar matriz de adyacencia cuando el grafo es disperso
Un grafo de redes sociales con 100 millones de usuarios jamás cabe en una matriz 100M × 100M. Siempre lista de adyacencia salvo razón muy específica.
2. Olvidar marcar vértices visitados
En grafos con ciclos, olvidar el set de visitados lleva a bucles infinitos. Todos los algoritmos de recorrido requieren esta verificación.
3. Confundir recorrido de árbol con recorrido de grafo
En un árbol, nunca hay ciclos, así que BFS/DFS no necesitan set de visitados. En grafos, sí. Portar código de árbol a grafo sin añadir el set es un bug común.
4. No distinguir dirigido vs no dirigido
Si el grafo es dirigido, agregarArista(u, v) no crea v → u. Duplicar aristas cuando es dirigido o no duplicar cuando es no dirigido lleva a resultados falsos.
5. Asumir que existe el camino más corto con Dijkstra y pesos negativos
Dijkstra requiere pesos no negativos. Con pesos negativos, falla silenciosamente. Usa Bellman-Ford.
6. Pensar que un "grafo con ciclos" es siempre un problema
Muchos grafos reales son cíclicos por naturaleza (mapas, redes sociales). El error no es tener ciclos; es no manejarlos.
7. Iterar vecinos sin checar si existen
adyacencia.get(v) puede devolver null si v no está en el grafo. Siempre usa getOrDefault o verifica.
Resumen
Un grafo es un conjunto de vértices y aristas. Puede ser dirigido o no, ponderado o no, cíclico o no. Se representa típicamente con lista de adyacencia para grafos dispersos y matriz para densos. Los recorridos fundamentales son BFS (por niveles, con cola) y DFS (en profundidad, con pila o recursión), ambos O(V + E).
Sobre grafos se construyen muchos de los algoritmos más útiles de la computación: caminos mínimos (Dijkstra, A*), árbol de expansión mínima (Kruskal, Prim), ordenamiento topológico, detección de ciclos, flujo máximo, PageRank. Google Maps, las redes sociales, los build systems, los compiladores, los sistemas de recomendación y los grafos de dependencias son aplicaciones cotidianas.
Con este artículo cerramos la Serie 2 Por dentro de las estructuras. En la Serie 3 Cómo se busca y se recorre nos concentramos en los algoritmos que exploran estas estructuras: lineal, binaria, recorridos de árbol, BFS y DFS. Nos vemos allá.
DFS: recorrido en profundidad, backtracking y la base de muchos algoritmos
Depth-First Search se sumerge hasta el fondo antes de retroceder. Usado en backtracking, detección de ciclos y ordenamiento topológico. Vers...
BFS: búsqueda por anchura en grafos y árboles
Breadth-First Search explora nivel por nivel usando una cola. Es la base de shortest path en grafos no ponderados y del recorrido por nivele...
Recorridos de árboles: inorden, preorden y postorden explicados
Las tres formas clásicas de visitar todos los nodos de un árbol binario. Cuál usar depende del orden en que necesitas los datos. Ejemplos co...
Comentarios (0)
Sé el primero en comentar.
Deja un comentario