Recursión: cuando una función se llama a sí misma
En el artículo anterior vimos cómo repetir un bloque de código con bucles. La recursión es la otra gran forma de repetir trabajo en programación: en lugar de usar un contador y un cuerpo, una función se llama a sí misma con un problema más pequeño, hasta que el problema es tan trivial que se puede resolver sin más llamadas.
Pensada así, la recursión suena a truco barato. En realidad es una herramienta profundamente poderosa, y para ciertos problemas —árboles, grafos, divide y vencerás— es la única forma elegante de escribir una solución. El precio que pagas es en memoria: cada llamada recursiva abre un stack frame, y ese detalle explica la mayoría de los bugs y crashes asociados a recursión.
La idea básica
Una función recursiva tiene siempre dos partes:
Caso base: la condición donde la función ya no se llama a sí misma, sino que retorna directamente un valor. Sin caso base, la recursión nunca termina.
Paso recursivo: la función se llama a sí misma con una entrada más pequeña o más cercana al caso base.
El ejemplo canónico es el factorial:
factorial(0) = 1 // caso base
factorial(n) = n * factorial(n - 1) // paso recursivo
En código:
// PHP
function factorial(int $n): int {
if ($n === 0) return 1; // caso base
return $n * factorial($n - 1); // paso recursivo
}
echo factorial(5); // 120
// Java
public static int factorial(int n) {
if (n == 0) return 1;
return n * factorial(n - 1);
}
El truco mental es confiar en que la llamada a factorial(n - 1) ya devuelve el resultado correcto. Una vez aceptas eso, solo tienes que combinar ese resultado con el valor actual. La recursión se vuelve casi una definición matemática escrita en código.
Cómo se vería en memoria
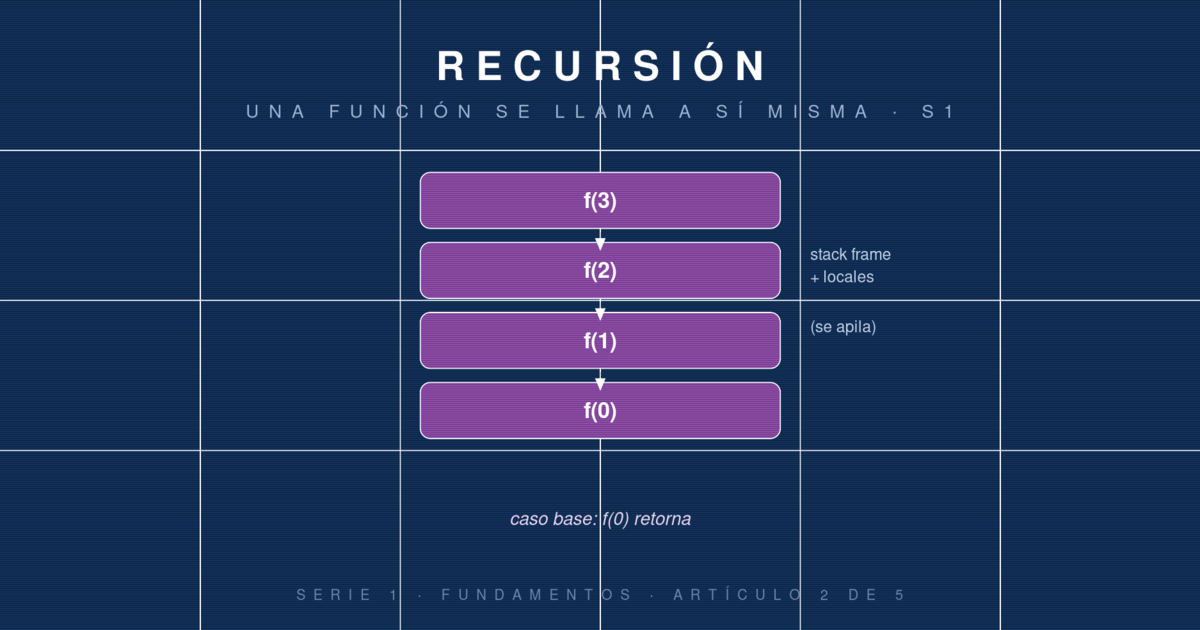
Aquí está la parte crítica que separa a quien usa recursión con criterio de quien solo la copia de Stack Overflow. Cada vez que una función se llama a sí misma, el runtime (la JVM en Java, el engine de PHP) abre un nuevo stack frame en la pila de ejecución.
Un stack frame contiene:
Los parámetros de la llamada (en nuestro caso, el valor de
n).Las variables locales de esa ejecución.
La dirección de retorno: a qué línea volver cuando la función termine.
Para factorial(5) el stack se ve así mientras baja:
| factorial(0) | ← caso base, retorna 1
| factorial(1) |
| factorial(2) |
| factorial(3) |
| factorial(4) |
| factorial(5) | ← llamada original
Cuando factorial(0) retorna, su frame se libera y el control vuelve a factorial(1), que ahora puede calcular 1 * 1 = 1 y retornar. Luego factorial(2) calcula 2 * 1 = 2, y así hacia arriba. Los frames se van desapilando como platos en una pila.
Este detalle tiene dos consecuencias prácticas:
La recursión consume memoria de stack proporcional a la profundidad de las llamadas. Para
factorial(5)son 6 frames. Parafactorial(10000)serían 10,001 frames y el stack de la JVM se desbordaría antes de llegar.Cada llamada tiene overhead. Reservar un frame, pasar parámetros, guardar la dirección de retorno… no es gratis. Un bucle equivalente casi siempre es más rápido que una versión recursiva ingenua.
Recursión vs iteración: cuándo usar cada una
La pregunta del millón. Mi heurística después de años viendo código:
Usa iteración cuando el problema es lineal: recorrer una colección, contar, acumular, filtrar. No hay razón para pagar el costo de stack frames si un
forhace exactamente lo mismo.Usa recursión cuando el problema se define naturalmente en términos de sí mismo: recorrer un árbol (cada subárbol es un árbol), navegar un grafo, backtracking, divide y vencerás (mergesort, quicksort).
Factorial es un ejemplo engañoso porque se puede hacer trivialmente con un bucle, y ese bucle será más rápido y seguro:
int factorialIterativo(int n) {
int resultado = 1;
for (int i = 2; i <= n; i++) resultado *= i;
return resultado;
}
Pero recorrer un árbol de archivos, evaluar una expresión matemática con paréntesis anidados o generar todas las permutaciones de un string son problemas donde la versión iterativa requiere simular manualmente una pila, mientras que la recursiva sale en 5 líneas.
Ejemplos donde la recursión brilla
Sumar los valores de una estructura anidada
function sumaAnidada(array $datos): int {
$total = 0;
foreach ($datos as $item) {
if (is_array($item)) {
$total += sumaAnidada($item);
} else {
$total += $item;
}
}
return $total;
}
echo sumaAnidada([1, [2, [3, 4]], 5]); // 15
Sin recursión tendrías que mantener una pila a mano para trackear en qué nivel vas. Con recursión, simplemente dejas que el runtime lo haga por ti.
Fibonacci (el ejemplo que todo tutorial usa)
public static int fib(int n) {
if (n < 2) return n;
return fib(n - 1) + fib(n - 2);
}
Elegante, sí, pero también una trampa didáctica. Esta versión ingenua de Fibonacci es O(2ⁿ): fib(50) tarda minutos porque recalcula los mismos valores miles de veces. Es el ejemplo perfecto de que la recursión bonita no siempre es la recursión correcta.
Fibonacci memoizado
Map<Integer, Integer> cache = new HashMap<>();
public int fib(int n) {
if (n < 2) return n;
if (cache.containsKey(n)) return cache.get(n);
int r = fib(n - 1) + fib(n - 2);
cache.put(n, r);
return r;
}
Con memoización baja a O(n) y el árbol de llamadas se colapsa. La lección: la recursión es solo una estructura de control; lo que gasta tiempo son las operaciones redundantes, y eso no lo arregla la recursión por sí sola.
Errores comunes
1. Olvidar el caso base (o ponerlo mal)
Es el error número uno. Sin caso base, la función se llama para siempre hasta que el stack revienta:
// PHP
PHP Fatal error: Maximum function nesting level of '256' reached
// Java
java.lang.StackOverflowError
A veces el caso base existe pero está mal formulado: la recursión avanza en la dirección equivocada, y nunca se alcanza. Revísalo con cuidado: ¿en cada llamada el argumento se acerca realmente al caso base?
2. Stack overflow con entradas grandes
Incluso con un caso base correcto, una recursión de 100,000 niveles va a romper el stack en casi cualquier lenguaje. La JVM tiene un stack de ~512 KB por defecto para cada thread, lo que permite entre 10,000 y 20,000 frames típicos. PHP tiene un límite más agresivo (256 por defecto, configurable con xdebug.max_nesting_level).
Si tu problema requiere profundidad mayor a unos miles, reconsidera: probablemente necesitas versión iterativa con una pila explícita en heap, o una recursión de cola (tema del siguiente artículo, aunque con matices importantes para Java y PHP).
3. Duplicar trabajo sin memoizar
Como vimos con Fibonacci ingenuo, una recursión que resuelve el mismo subproblema varias veces es una bomba de performance. Si ves que tus llamadas recursivas se solapan, agrega un cache o reescribe la lógica con programación dinámica.
4. Mutar estado compartido
Pasar una variable global o una referencia que se modifica entre llamadas recursivas hace el código extremadamente difícil de razonar. La recursión limpia es aquella donde cada llamada solo depende de sus parámetros y devuelve un valor. Si necesitas acumular, pasa el acumulador como parámetro:
// Mejor: el estado fluye por el parámetro
public int sumaLista(List<Integer> xs, int acumulador) {
if (xs.isEmpty()) return acumulador;
return sumaLista(xs.subList(1, xs.size()), acumulador + xs.get(0));
}
5. Creer que recursión es siempre "más elegante"
La recursión tiene un halo de sofisticación que a veces engaña. Código recursivo innecesariamente complejo es peor que código iterativo claro. La regla: si la versión iterativa es obvia, úsala. Reserva la recursión para cuando el problema tiene estructura recursiva natural.
Recursión mutua
Un caso especial: dos funciones que se llaman entre sí. Es útil para modelar máquinas de estado o gramáticas, pero requiere disciplina porque el stack trace se vuelve más difícil de leer.
function esPar(int $n): bool {
if ($n === 0) return true;
return esImpar($n - 1);
}
function esImpar(int $n): bool {
if ($n === 0) return false;
return esPar($n - 1);
}
Mismo principio: cada llamada baja una unidad hasta llegar al caso base. La memoria de stack crece con n, así que para números grandes sigue siendo peligroso.
Resumen
Una función recursiva es una función que se llama a sí misma, con un caso base que detiene la cadena y un paso recursivo que reduce el problema. En memoria, cada llamada abre un stack frame, y eso limita la profundidad práctica que puedes alcanzar.
La recursión brilla en problemas con estructura recursiva natural (árboles, grafos, divide y vencerás) y pierde frente a la iteración en bucles lineales simples. Los errores más comunes son olvidar el caso base, desbordar el stack con entradas grandes, duplicar trabajo sin memoizar y escribir recursión solo por vanidad.
En el siguiente artículo vemos una variante especial —la recursión de cola— que en algunos lenguajes permite evitar el crecimiento del stack. Spoiler: no funciona en Java ni en PHP, y eso cambia cómo la usas.
DFS: recorrido en profundidad, backtracking y la base de muchos algoritmos
Depth-First Search se sumerge hasta el fondo antes de retroceder. Usado en backtracking, detección de ciclos y ordenamiento topológico. Vers...
BFS: búsqueda por anchura en grafos y árboles
Breadth-First Search explora nivel por nivel usando una cola. Es la base de shortest path en grafos no ponderados y del recorrido por nivele...
Recorridos de árboles: inorden, preorden y postorden explicados
Las tres formas clásicas de visitar todos los nodos de un árbol binario. Cuál usar depende del orden en que necesitas los datos. Ejemplos co...
Comentarios (0)
Sé el primero en comentar.
Deja un comentario