Tablas hash: cómo encontrar algo en O(1) usando matemáticas
Si algún día alguien te pregunta por qué los lenguajes modernos son tan rápidos manipulando objetos, datos, configuraciones y caches, la respuesta corta es "tablas hash". Son la estructura de datos que convierte la búsqueda por llave en una operación prácticamente instantánea, sin importar si tu estructura tiene 10 o 10 millones de entradas.
En PHP los arrays asociativos son tablas hash por defecto. En Java, HashMap y HashSet. En Python, dict y set. En JavaScript, los objetos y Map. En Go, los map[K]V. Todos resuelven el mismo problema de fondo con la misma idea matemática.
Este es el quinto artículo de la serie Por dentro de las estructuras. Ya vimos arrays, listas enlazadas, pilas y colas. Ahora toca la estructura más mágica y, si se usa mal, la más peligrosa.
El problema que resuelven
Imagina que tienes un millón de usuarios y quieres encontrar a Ana Pérez por su correo electrónico. Si tienes un array lineal de objetos Usuario, necesitas recorrerlo elemento por elemento: O(n) en el peor caso. Un millón de comparaciones para encontrar uno.
Si mantienes los usuarios ordenados por correo, puedes hacer búsqueda binaria: O(log n). Veinte comparaciones en lugar de un millón. Mejora enorme, pero mantener ordenado un array conlleva inserciones O(n).
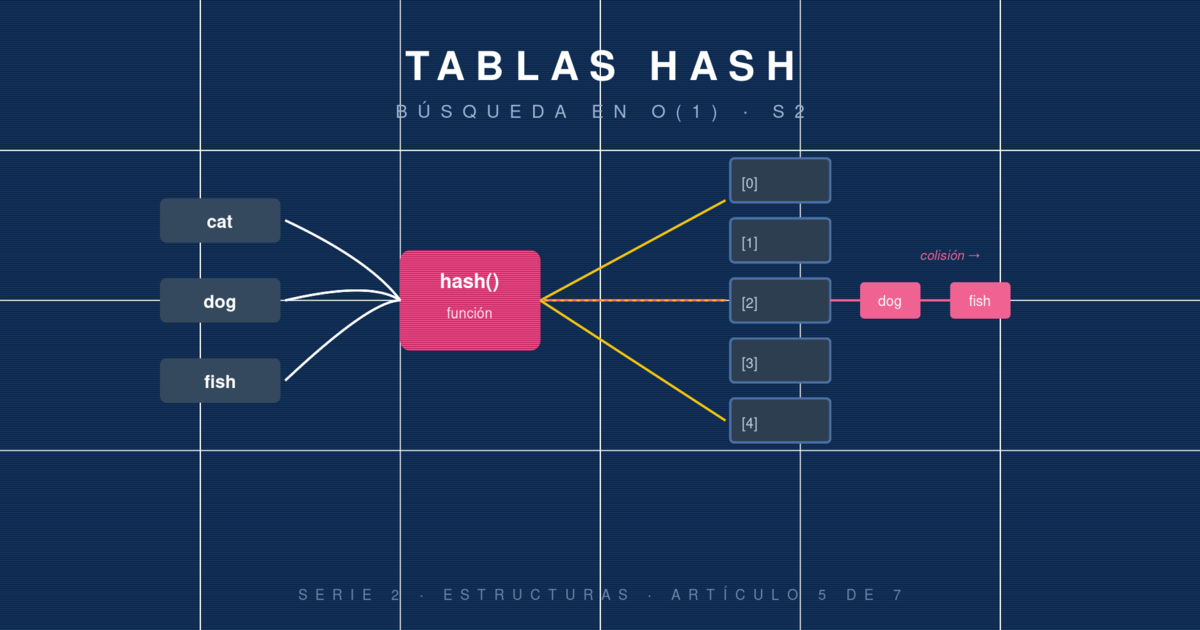
¿Y si pudieras calcular directamente, a partir del correo, la posición en la que está el usuario? Entonces una simple aritmética te daría la respuesta. Eso es una tabla hash: una estructura que usa una función hash para traducir una llave (como un correo) a un índice de array (como la posición 42,891).
La idea central
Una tabla hash se compone de:
Un array de buckets (cubetas) de tamaño fijo, digamos
m.Una función hash
h(llave)que devuelve un entero entre 0 ym−1.Una política de manejo de colisiones, porque dos llaves distintas pueden caer en el mismo bucket.
Para insertar un par (llave, valor):
Calculas
indice = h(llave) mod m.Guardas el par en
buckets[indice].
Para buscar:
Calculas el mismo
indice.Miras en
buckets[indice].
Si la función hash distribuye bien, llegas a cada entrada en una operación: O(1).
Cómo se vería en memoria
Imagina una tabla con 8 buckets y queremos insertar ("ana@x.com", 1), ("bruno@x.com", 2), ("clara@x.com", 3).
indice = hash("ana@x.com") mod 8 → 3
indice = hash("bruno@x.com") mod 8 → 6
indice = hash("clara@x.com") mod 8 → 3 ← colisión!
Con encadenamiento separado (la política más común), cada bucket es una lista enlazada:
buckets:
0: null
1: null
2: null
3: [ana@x.com → 1] → [clara@x.com → 3]
4: null
5: null
6: [bruno@x.com → 2]
7: null
Cuando buscas "clara@x.com", calculas el hash (3), saltas al bucket 3 y recorres la cadena hasta encontrar la llave exacta. Si hay pocas colisiones, esa cadena tiene 1–2 elementos y sigue siendo O(1) en la práctica.
La función hash: el corazón de todo
Una buena función hash cumple tres propiedades:
Determinista: la misma llave da siempre el mismo resultado.
Uniforme: distribuye las llaves de manera pareja sobre los
mbuckets.Rápida: calcular el hash es O(1) respecto al tamaño de la tabla.
En Java, todo objeto tiene un método hashCode() que devuelve un int. Para un String, se calcula con el polinomio clásico:
h = 0
para cada caracter c:
h = 31 * h + c
Luego Java toma el hash y lo "compacta" al rango de buckets con (hash & (m − 1)), asumiendo que m es potencia de 2.
En PHP, las llaves pueden ser strings o enteros; internamente Zend Engine usa una función hash DJBX33A (una variación de la familia DJB2) para strings.
Manejo de colisiones
Incluso con una función hash perfecta, las colisiones ocurren por el problema del cumpleaños: con 23 personas en una sala, la probabilidad de que dos compartan cumpleaños supera el 50%. Trasládalo a una tabla hash: con pocas llaves ya aparecen colisiones.
Hay dos familias de estrategias:
1. Encadenamiento separado (separate chaining)
Cada bucket es una lista (o árbol). Es la solución más fácil de implementar y la que usa Java hasta cierto umbral: cuando una cadena supera 8 elementos, Java 8+ la convierte internamente en un árbol rojo-negro para mantener búsqueda O(log n) en el peor caso.
bucket[3]: [ana → 1] → [clara → 3] → [dante → 4]
2. Direccionamiento abierto (open addressing)
No usa listas: si hay colisión, busca el siguiente bucket libre según una regla (linear probing, quadratic probing, double hashing). Python y algunas implementaciones usan esta estrategia porque tiene mejor localidad de cache.
bucket 3: ana (llena)
bucket 4: clara (antes vacía, colocada aquí por colisión)
bucket 5: ...
La desventaja es que hay que redimensionar la tabla más agresivamente para evitar clusters.
El factor de carga y el rehashing
El factor de carga es n / m: cuántos elementos por bucket. Cuando sube demasiado (0.75 es el umbral típico en Java), las colisiones se multiplican y el rendimiento se degrada.
La solución es rehashing: al superar el umbral, Java dobla el tamaño del array (m → 2m) y recalcula los índices de todos los elementos. Es O(n), pero ocurre raramente; amortizado, las inserciones siguen siendo O(1).
Este coste ocasional explica por qué, si sabes de antemano cuántos elementos vas a meter, es mejor pre-dimensionar la tabla:
Map<String, Integer> usuarios = new HashMap<>(1_000_000);
Así evitas varios ciclos de rehashing cuando el mapa crece.
Implementación en PHP
En PHP, los arrays ya son tablas hash ordenadas:
$usuarios = [
"ana@x.com" => 1,
"bruno@x.com" => 2,
"clara@x.com" => 3,
];
$usuarios["dante@x.com"] = 4;
if (isset($usuarios["ana@x.com"])) {
echo $usuarios["ana@x.com"]; // 1
}
unset($usuarios["bruno@x.com"]);
foreach ($usuarios as $correo => $id) {
echo "$correo → $id\n";
}
Por debajo es una tabla hash con listas doblemente enlazadas para preservar el orden de inserción. No necesitas hacer nada especial: todas las operaciones (isset, =>, unset) son O(1) amortizado.
Si quieres una tabla hash más estricta con objetos como llaves, usa SplObjectStorage:
$store = new SplObjectStorage();
$usuario = new Usuario("Ana");
$store[$usuario] = "permiso de admin";
echo $store[$usuario];
Implementación en Java
import java.util.HashMap;
import java.util.Map;
Map<String, Integer> usuarios = new HashMap<>();
usuarios.put("ana@x.com", 1);
usuarios.put("bruno@x.com", 2);
usuarios.put("clara@x.com", 3);
Integer id = usuarios.get("ana@x.com"); // 1
boolean existe = usuarios.containsKey("x@x"); // false
usuarios.remove("bruno@x.com");
for (Map.Entry<String, Integer> e : usuarios.entrySet()) {
System.out.println(e.getKey() + " → " + e.getValue());
}
Variantes importantes en Java:
HashMap: el default. No garantiza orden. Rápido, no thread-safe.
LinkedHashMap: preserva el orden de inserción. Ligeramente más lento; útil para caches LRU.
TreeMap: no es hash, es un árbol rojo-negro. Mantiene las llaves ordenadas. O(log n), no O(1). Úsalo si necesitas iterar ordenadamente.
ConcurrentHashMap: thread-safe con segmentación interna. Úsalo para escenarios multihilo sin bloquear todo el mapa.
HashSet: mismo principio, pero solo guardas llaves (sin valor). Implementado internamente sobre un HashMap.
Cómo implementa Java las llaves personalizadas
Si quieres usar un objeto propio como llave, debes sobrescribir dos métodos: equals y hashCode. La regla de oro:
si a.equals(b) es verdadero, entonces a.hashCode() == b.hashCode().
Si violas esta regla, el mapa no encontrará tus entradas aunque estén ahí:
class Usuario {
String correo;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Usuario u)) return false;
return correo.equals(u.correo);
}
@Override
public int hashCode() {
return correo.hashCode();
}
}
En IDEs modernos, Alt+Insert → equals/hashCode los genera automáticamente. O usa records en Java 17+:
record Usuario(String correo) {} // equals y hashCode automáticos
Operaciones y su costo
OperaciónPromedioPeor casoget(k)O(1)O(n)put(k, v)O(1)O(n)remove(k)O(1)O(n)containsKey(k)O(1)O(n)IterarO(m + n)O(m + n)
El peor caso O(n) ocurre cuando todas las llaves colisionan en el mismo bucket. En la práctica, con una buena función hash y un factor de carga razonable, nunca lo ves. En Java 8+, el peor caso efectivo bajó a O(log n) gracias a la conversión a árbol de los buckets muy poblados.
Ventajas y desventajas
Ventajas:
Búsqueda, inserción y borrado O(1) promedio.
Acceso por llave arbitraria (no solo por índice entero).
Muy flexible: casi cualquier cosa "mapeable" se modela bien.
Desventajas:
No mantienen orden (salvo variantes como
LinkedHashMap).Peor caso degradado si la función hash es mala o un atacante controla las llaves (hash collision DoS).
Consumen más memoria que un array: overhead por bucket + entries + punteros.
Iterar es impredecible en orden y más lento que sobre un array contiguo.
Calcular el hash tiene un costo constante, pero real; para llaves muy cortas o datos muy simples, a veces un array es más rápido.
Casos de uso reales
Caches en memoria: mapear una URL a su respuesta HTTP, un ID a un objeto cacheado.
Conteo de frecuencias: contar cuántas veces aparece cada palabra en un texto, cada IP en un log.
Índices en memoria: en bases de datos y motores de búsqueda, estructuras hash aceleran los joins.
Dedupe: usar un
HashSetpara detectar elementos repetidos en O(n).Diccionarios de configuración: cada clave de entorno, feature flag o traducción.
Memoización: guardar resultados ya calculados en un mapa para evitar recomputación.
Routing: mapear una ruta HTTP a un handler.
Implementación interna de conjuntos (
Set) en la mayoría de lenguajes.
Ejemplo completo: contador de palabras
import java.util.HashMap;
import java.util.Map;
public class ContadorPalabras {
public static Map<String, Integer> contar(String texto) {
Map<String, Integer> conteo = new HashMap<>();
for (String palabra : texto.toLowerCase().split("\\W+")) {
if (palabra.isEmpty()) continue;
conteo.merge(palabra, 1, Integer::sum);
}
return conteo;
}
public static void main(String[] args) {
Map<String, Integer> r = contar("La lluvia en Sevilla es una maravilla, la lluvia es pura.");
r.forEach((k, v) -> System.out.println(k + " → " + v));
}
}
El método merge suma 1 si la palabra existe, o la inserta con valor 1 si no. Este patrón es uno de los más idiomáticos en Java moderno.
Cómo recorrer una tabla hash
En PHP con foreach:
foreach ($usuarios as $correo => $id) {
echo "$correo → $id\n";
}
En Java, hay tres formas:
// 1. Iterar entries (lo más común)
for (Map.Entry<String, Integer> e : map.entrySet()) { ... }
// 2. Iterar solo llaves
for (String k : map.keySet()) { ... }
// 3. Iterar solo valores
for (Integer v : map.values()) { ... }
// 4. API funcional (Java 8+)
map.forEach((k, v) -> System.out.println(k + ": " + v));
Recuerda: HashMap no garantiza orden. Si necesitas recorrer en orden de inserción usa LinkedHashMap; si necesitas orden por llave, TreeMap.
Errores comunes
1. Olvidar sobrescribir hashCode() junto con equals()
Es el error clásico en Java. Si sobrescribes equals pero dejas el hashCode heredado de Object (que devuelve algo aleatorio por instancia), tu mapa nunca encontrará los valores. Siempre juntos.
2. Usar un objeto mutable como llave y mutarlo después
Si metes un objeto en el mapa y luego modificas un campo que afecta a su hashCode, el mapa lo pierde. El objeto está ahí, pero el hash ya no coincide con el bucket. Usa objetos inmutables como llaves o, como mínimo, no modifiques los campos que participan en equals/hashCode.
3. Asumir O(1) sin pensar en el hashCode
Si tu hashCode siempre devuelve 0, todas las llaves colisionan y el mapa se convierte en una lista: O(n) para todo. Mide el coste real en escenarios sensibles.
4. Usar HashMap en código concurrente
No es thread-safe. En condiciones de carrera puede incluso entrar en un bucle infinito (ocurrió en Java 7 con el método resize). Usa ConcurrentHashMap o sincroniza accesos.
5. Exponer una tabla hash a entradas controladas por un atacante
Si el atacante puede elegir llaves que colisionen (hash flooding), degrada tu mapa a O(n²) y puede tumbar un servidor. Lenguajes modernos mitigan con hashing aleatorio por proceso (PHP lo hace desde 7.0), pero si implementas hash manualmente, ten cuidado.
6. Iterar mientras modificas
map.remove(k) dentro de un for (k : map.keySet()) lanza ConcurrentModificationException. Usa Iterator.remove() o acumula las llaves a borrar en una lista aparte.
Resumen
Las tablas hash convierten una llave en un índice mediante una función hash y almacenan los datos en un array de buckets. Manejan colisiones con encadenamiento (listas/árboles) o direccionamiento abierto. Ofrecen get, put y remove en O(1) promedio y son la estructura más usada en software moderno: arrays asociativos de PHP, HashMap y HashSet de Java, dicts de Python, objetos de JavaScript.
Para aprovecharlas bien: elige buenas llaves (inmutables), implementa equals/hashCode correctamente en Java, dimensiona con capacidad inicial conocida, y usa variantes concurrentes en escenarios multihilo.
En el siguiente artículo saltamos a estructuras jerárquicas: los árboles. Son la base de sistemas de archivos, parsers, bases de datos y motores de búsqueda.
DFS: recorrido en profundidad, backtracking y la base de muchos algoritmos
Depth-First Search se sumerge hasta el fondo antes de retroceder. Usado en backtracking, detección de ciclos y ordenamiento topológico. Vers...
BFS: búsqueda por anchura en grafos y árboles
Breadth-First Search explora nivel por nivel usando una cola. Es la base de shortest path en grafos no ponderados y del recorrido por nivele...
Recorridos de árboles: inorden, preorden y postorden explicados
Las tres formas clásicas de visitar todos los nodos de un árbol binario. Cuál usar depende del orden en que necesitas los datos. Ejemplos co...
Comentarios (0)
Sé el primero en comentar.
Deja un comentario